
Hosted by Jeff Shepard, EE World has organized this “virtual conversation” with Gary Bronner (GB), Senior Vice President with Rambus Labs. Mr. Bronner has generously agreed to share his experience and insights into AI applications and emerging computing architectures.
JS: What is usually the biggest challenge designers face when first using artificial intelligence?

GB: One of the biggest challenges designers face when first using AI is that it requires a careful balancing of processing and memory. A fast AI accelerator needs a memory system feeding it enough data to stay busy. It is very hard to get the ratio of accelerator performance to memory bandwidth right, or even know what it should be unless you understand the specific problem you are working on and what the workloads will be. This is why memory, or, more precisely, the type of memory, is so important for AI. Both GDDR6 and HBM2 are widely used in AI systems. The choice between them comes down to tradeoffs in cost, power, chip area, and design complexity.
JS: What is the most misunderstood aspect of AI, and how does that translate into specific design challenges?
GB: A common misconception is that all AI or deep learning applications work the same. Depending on whether you are doing image recognition or speech or translation or any of the other applications of deep learning, the architecture that will work best for a specific system is actually very different. There are several approaches that can significantly change the architecture of the system. So when you design hardware, you can’t just think of one. For example, you could build the best machine for convolutional networks that will allow you to do great image recognition. However, it wouldn’t work as well if you used the same machine as a translator.
The other thing that is important to remember is that the field is still evolving, with new algorithms being produced almost every day. How do you design a system to be useful for algorithms that haven’t been invented yet? Some of the ability to answer that question depends on how good your crystal ball is.
More practically, it translates to keeping in mind how much bandwidth you need today as well as how much you’ll need in the future. Architecturally, it’s about figuring out how to flexibly route resources around the various compute elements. For example, the higher performance of an AI accelerator means it needs more and more data to keep itself busy and productive. Which drives the need for high-performance memory systems, and very high bandwidth memory interfaces, either GDDR6 or various HBMx generations, both of which Rambus helps enable.
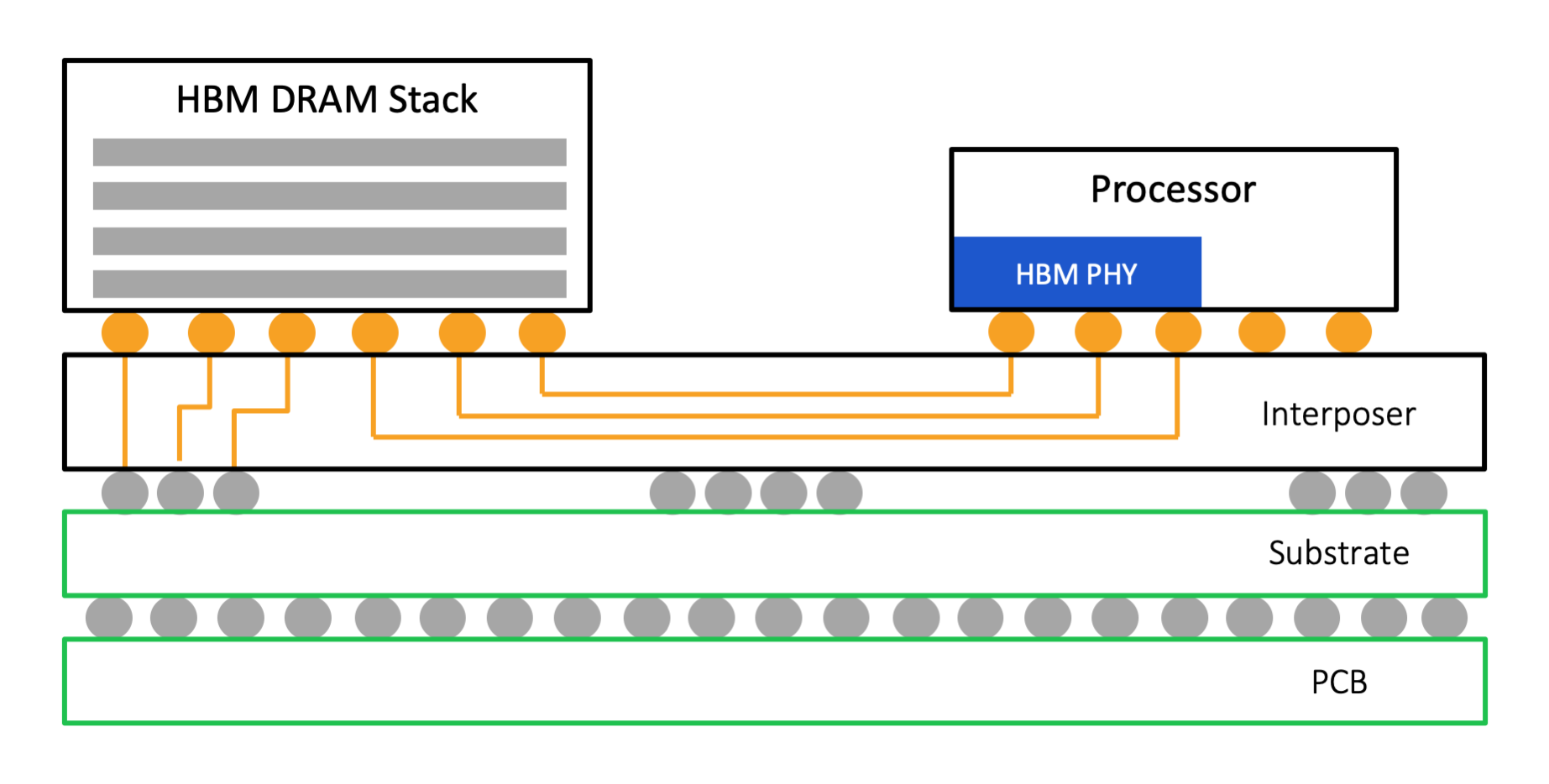
What it ultimately boils down to is you need to design a system that is very optimized, but not completely specialized, to provide some added flexibility.
JS: Considering AI accelerators using CPUs, GPUs, and FPGAs, what are the tradeoffs in terms of specific application features and benefits of each of those approaches?
GB: As the saying goes, “you can have something done cheap, fast, or right – pick two.” The same concept applies here; AI accelerators can be fast, energy-efficient, or flexible, but not all three.
CPUs are general-purpose, so they are the least expensive but provide the lowest performance for AI and are the least power efficient. FPGAs offer better performance and power efficiency compared to CPUs, but they are not as performant as GPUs. However, they offer a level of flexibility that makes them good for prototyping or addressing the rapidly evolving algorithms. As a result, we’re currently seeing FPGAs used frequently for AI accelerators. GPUs lack the flexibility of FPGAs but offer better performance and power efficiency.
I think there is actually a fourth approach to build an AI accelerator – custom ASICs. An ASIC is probably the highest performance and highest efficiency approach once you are confident that the algorithms are relatively set. The challenge with them is it can take six months to design an ASIC, by which point the algorithm it was designed for would be too old, and the process would have to be started over.
JS: Do you expect to see new computing architectures emerge optimized specifically for AI? If so, what should we expect to see in this area?
GB: Yes, we are already seeing what is being referred to as a new “golden age of computing,” which is resulting in many specialized chips. We are seeing this tremendous need for ever-increasing performance that is manifesting in new technology such as Google’s TPU, startups such as Cerebras Systems, along with probably more than 30 or 40 other designs in various stages of deployment. These applications are good at running AI, and because there is such high demand, there’s an astonishing ability to fund it, continuing to drive performance and efficiency.
This can be further broken down into data center and edge. At the edge, the big concern is achieving efficient implementation of machine learning functions for more inference tasks. For example, we need Alexa to recognize the “hot word.” Whereas what is important in the data center—where the training takes place—is attaining the highest performance to improve machine learning algorithms.
Right now, the number of architectures is growing rapidly as the industry evolves and tries to figure out what’s going to ultimately work best. This will eventually lead to a kind of natural selection where we’ll see a few of the best solutions become de facto standards.
JS: Thank you to Mr. Bronner, for sharing his insights and experience, great conversation! You might also be interested in reading “Measuring the performance of AI and its impact on society” Virtual Conversation (part 2 of 2).





Leave a Reply