
Artificial intelligence (AI) systems face a set of conflicting goals: being accurate (consuming large amounts of computational power and electrical power) and being accessible (being lower in cost, less computationally intensive, and less power-hungry). Unfortunately, many of today’s AI implementations are environmentally unsustainable. Improvements in AI energy efficiency will be driven by several factors, including more efficient algorithms, more efficient computing architectures, and more efficient components.
It’s necessary to measure and track the energy consumption of AI systems to identify any improvements in energy efficiency. One example of the increasing awareness of the importance of energy consumption in AI systems is having is reflected in the fact that the ULPMark (ultra-low power) benchmark line from EEMBC is now adding ML inference and developing a new benchmark, the ULPMark-ML. The effort to standardize what is known as “tinyML” or lower power ML is underway, with a dozen companies participating in EEMBC’s effort. The goal of this benchmark is to create a standardized suite of tasks that will measure a device’s inference energy-efficiency as a single figure of merit. This is expected to be useful from the cloud to the edge.
More efficient algorithms
Dr. Max Welling, Vice President, Technology, with Qualcomm, believes that the benchmark for AI processing could soon change and that AI algorithms will be measured by the amount of intelligence they provide per joule. He cites two key reasons for this:
- First, broad economic viability requires energy-efficient AI since the value created by AI must exceed the cost to run the service. To put this in perspective, the economic feasibility of applying AI per transaction may require a cost as low as a micro dollar (1/10,000th of a cent). An example of this is using AI for personalized advertisements and recommendations.
- Second, on-device AI processing in sleek, ultra-light mobile form factors requires power efficiency. Processing always-on compute-intensive workloads in power- and thermal-constrained form factors that require all-day battery life is part of making AI adopted by consumers more broadly. The same power efficiency attributes are needed for other classes of devices, such as autonomous cars, drones, and robots.
To date, much of the research related to AI has been independently working to improve algorithms, software, and hardware. In the future, it will be necessary to optimize all three dimensions simultaneously. That will require new AI computing architectures as well as improved algorithms.
Lower power AI computing architectures and memories
“In-memory computing” or “computational memory” is an emerging concept that uses the physical properties of memory devices for both storing and processing information. This is counter to current von Neumann systems and devices, such as standard desktop computers, laptops, and even cellphones, which shuttle data back and forth between memory and the computing unit, thus making them slower and less energy efficient.

Scientists at IBM Research have demonstrated that an unsupervised machine-learning algorithm, running on one million phase change memory (PCM) devices, successfully found temporal correlations in unknown data streams. When compared to state-of-the-art classical computers, this prototype technology is expected to yield 200x improvements in both speed and energy efficiency, making it highly suitable for enabling ultra-dense, low-power, and massively-parallel computing systems for applications in AI.
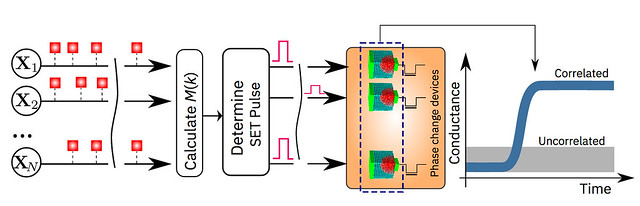
The PCM devices were made from a germanium antimony telluride alloy, which is stacked and sandwiched between two electrodes. When the scientists apply a tiny electric current to the material, they heat it, which alters its state from amorphous (with a disordered atomic arrangement) to crystalline (with an ordered atomic configuration). The IBM researchers have used the crystallization dynamics to perform computation in place.
AI and ML systems consume large quantities of computer memory. Low power magnetoresistive random access memories (MRAMs) are a relatively new technology that can support the memory needs of AI and ML systems, especially at the Edge. Since it’s currently slower than DRAM or SRAM, MRAM may not find immediate application in the cloud, but for edge devices, it could provide a boost for AI implementations. MRAM combines the attributes of low latencies, low power consumption, high endurance, and memory persistence that are well suited for Edge AI systems.
Internet of Things (IoT) nodes that include ML could be enabled by MRAM’s persistence (data retention capability is greater than 20 years at 85°C). With MRAM, ML algorithms do not have to be reloaded every time the device comes out of sleep mode, saving both time and energy. This could enable IoT nodes to analyze sensor data and make quick high-level decisions locally in real-time. More in-depth analysis and refined decisions would rely on a connection to the cloud.
The speed of MRAM is beneficial for implementing machine learning in edge devices in factory automation, automotive, and other systems. In these systems, data is analyzed, and intermediate patterns are identified and shared with adjacent domains. The edge architecture requires a speed of processing and persistent memory, which can be supported by MRAM.
That wraps up this three-part series on artificial intelligence and machine learning. You might also enjoy reading part one, “Artificial Intelligence, Machine Learning, Deep Learning, and Cognitive Computing” and part two, “Benchmarking AI from the Edge to the Cloud.”
References:
Green AI, Allen Institute for AI, Carnegie Mellon University and University of Washington
How algorithmic advances make power-efficient AI possible, Qualcomm
IBM Scientists Demonstrate In-memory Computing with 1 Million Devices for Applications in AI, IBM





Leave a Reply