
 NVIDIA unveiled the NVIDIA A100 80GB GPU — the latest innovation powering the NVIDIA HGX AI supercomputing platform — with twice the memory of its predecessor, providing researchers and engineers unprecedented speed and performance to unlock the next wave of AI and scientific breakthroughs.
NVIDIA unveiled the NVIDIA A100 80GB GPU — the latest innovation powering the NVIDIA HGX AI supercomputing platform — with twice the memory of its predecessor, providing researchers and engineers unprecedented speed and performance to unlock the next wave of AI and scientific breakthroughs.
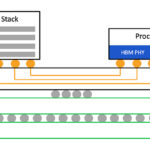
The new A100 with HBM2e technology doubles the A100 40GB GPU’s high-bandwidth memory to 80GB and delivers over 2 terabytes per second of memory bandwidth. This allows data to be fed quickly to A100, the world’s fastest data center GPU, enabling researchers to accelerate their applications even faster and take on even larger models and datasets.
The NVIDIA A100 80GB GPU is available in NVIDIA DGX A100 and NVIDIA DGX Station A100 systems and expected to ship this quarter.
Leading systems providers Atos, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Inspur, Lenovo, Quanta, and Supermicro are expected to begin offering systems built using HGX A100 integrated baseboards in four- or eight-GPU configurations featuring A100 80GB in the first half of 2021.
Building on the diverse capabilities of the A100 40GB, the 80GB version is ideal for a wide range of applications with enormous data memory requirements.
For AI training, recommender system models like DLRM have massive tables representing billions of users and billions of products. A100 80GB delivers up to a 3x speedup, so businesses can quickly retrain these models to deliver highly accurate recommendations.
The A100 80GB also enables training of the largest models with more parameters fitting within a single HGX-powered server such as GPT-2, a natural language processing model with superhuman generative text capability. This eliminates the need for data or model parallel architectures that can be time-consuming to implement and slow to run across multiple nodes.
With its multi-instance GPU (MIG) technology, A100 can be partitioned into up to seven GPU instances, each with 10GB of memory. This provides secure hardware isolation and maximizes GPU utilization for a variety of smaller workloads. For AI inferencing of automatic speech recognition models like RNN-T, a single A100 80GB MIG instance can service much larger batch sizes, delivering 1.25x higher inference throughput in production.
On a big data analytics benchmark for retail in the terabyte-size range, the A100 80GB boosts performance up to 2x, making it an ideal platform for delivering rapid insights on the largest of datasets. Businesses can make key decisions in real-time as data is updated dynamically.
For scientific applications, such as weather forecasting and quantum chemistry, the A100 80GB can deliver massive acceleration. Quantum Espresso, a materials simulation, achieved throughput gains of nearly 2x with a single node of A100 80GB.
Key Features of A100 80GB
The A100 80GB includes the many groundbreaking features of the NVIDIA Ampere architecture: Third-Generation Tensor Cores: Provide up to 20x AI throughput of the previous Volta generation with a new format TF32, as well as 2.5x FP64 for HPC, 20x INT8 for AI inference, and support for the BF16 data format; Larger, Faster HBM2e GPU Memory: Doubles the memory capacity and is the first in the industry to offer more than 2TB per second of memory bandwidth; MIG technology: Doubles the memory per isolated instance, providing up to seven MIGs with 10GB each; Structural Sparsity: Delivers up to a 2x speedup inferencing sparse models; Third-Generation NVLink and NVSwitch: Provide twice the GPU-to-GPU bandwidth of the previous generation interconnect technology, accelerating data transfers to the GPU for data-intensive workloads to 600 gigabytes per second
The A100 80GB GPU is a key element in NVIDIA HGX AI supercomputing platform, which brings together the full power of NVIDIA GPUs, NVIDIA NVLink, NVIDIA InfiniBand networking, and a fully optimized NVIDIA AI and HPC software stack to provide the highest application performance. It enables researchers and scientists to combine HPC, data analytics, and deep learning computing methods to advance scientific progress.



Leave a Reply