Firmware bugs. They’re the infamous ghosts in the machine that loom large in every developer’s mind. Firmware bugs can have catastrophic consequences for IoT devices, especially safety-critical systems such as automobiles and medical equipment, and they can be incredibly difficult to find and kill. To add to the issue, sometimes the root cause damages the code or data in such a subtle way that the system still appears to work fine – or mostly fine – for some time before the malfunction.
That’s why it’s important to understand the sources of common bugs – it‘s the first step to eliminating them. Here’s a look at some frequent root causes of difficult-to-reproduce firmware bugs — and best practices to prevent them.
#1: Stack Overflow
Every programmer knows that a stack overflow is a Very Bad Thing. But the nature of the damage and the timing of the misbehavior depend entirely on which data or instructions are clobbered and how they are used.
Unfortunately, stack overflow afflicts embedded systems far more often than it does desktop computers, for several reasons:
- Embedded systems usually use a smaller amount of RAM
- There is typically no virtual memory to fall back on (because there is no disk)
- Firmware designs based on RTOS tasks utilize multiple stacks (one per task), each of which must be sized sufficiently to ensure against unique worst-case stack depth
- Interrupt handlers may try to use those same stacks
Furthermore, no amount of testing can ensure that a particular stack is sufficiently large. You can test your system under different loading conditions but you can only test it for so long. Demonstrating that a stack overflow will never occur can, under algorithmic limitations (such as no recursion), be done with a top down analysis of the control flow of the code — but it will need to be redone every time the code is changed.
Best Practice: On startup, paint an unlikely memory pattern throughout the stack(s). (I like to use hex 23 3D 3D 23, which looks like a fence ‘#==#’ in an ASCII memory dump.) At runtime, have a supervisor task periodically check that none of the paint above some pre-established high water mark has been changed. Log any errors (e.g., which stack and how high the flood) in non-volatile memory and implement protection for users of the product (e.g., controlled shut down or reset).
#2: Race Condition
A race condition is any situation in which the combined outcome of two or more threads of execution (which can be either RTOS tasks or main() plus an ISR) varies depending on the precise order in which the instructions of each are interleaved.
For example, suppose you have two threads of execution in which one regularly increments a global variable (g_counter += 1;) and the other occasionally resets it (g_counter = 0;). There is a race condition here if the increment cannot always be executed atomically (i.e., in a single instruction cycle). A collision between the two updates of the counter variable may never or only very rarely occur. But when it does, the counter will not actually be reset in memory; therefore, its value is corrupt. This may have serious consequences for the system, though perhaps not until long after the actual collision.
Best Practice: Race conditions can be prevented by surrounding the “critical sections” of code that must be executed atomically with an appropriate preemption-limiting pair of behaviors. To prevent a race condition involving an ISR, at least one interrupt signal must be disabled for the duration of the other code’s critical section. In the case of a race between RTOS tasks, create a mutex specific to that shared object, which each task must acquire before entering the critical section. Don’t rely on the capabilities of a specific CPU to ensure atomicity, as that only prevents the race condition until a change of compiler or CPU.
Shared data and the random timing of preemption are culprits that cause the race condition. But the error might not always occur, making tracking down such bugs difficult. It is, therefore, important to be ever-vigilant about protecting all shared objects.
Also, name all potentially shared objects—including global variables, heap objects, or peripheral registers and pointers to the same—so the risk is immediately obvious to every future reader of the code. Barr Group’s Embedded C Coding Standard advocates the use of a ‘g_‘ prefix for this purpose.
#3: Non-Reentrant Function
Technically, the problem of a non-reentrant function is a special case of the problem of a race condition. For that reason, the run-time errors caused by a non-reentrant function are similar and also don’t occur in a reproducible way—making them just as hard to debug. Unfortunately, a non-reentrant function is also more difficult to spot in a code review than other types of race conditions.
Figure 1 shows a typical scenario. Here the software entities subject to preemption are RTOS tasks. But rather than manipulating a shared object directly, they do so by way of function call indirection. For example, suppose that Task A calls a sockets-layer protocol function, which calls a TCP-layer protocol function, which calls an IP-layer protocol function, which calls an Ethernet driver. In order for the system to behave reliably, all of these functions must be reentrant.
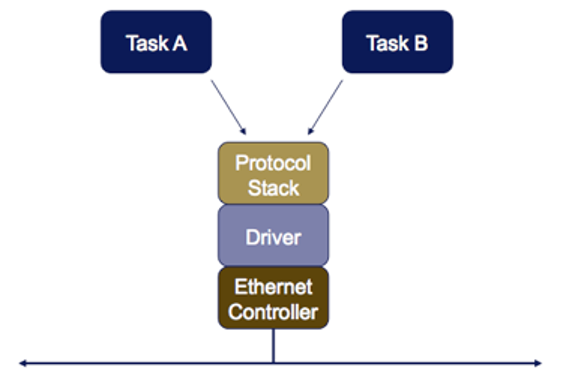
But the functions of the driver module manipulate the same global object in the form of the registers of the Ethernet Controller chip. If preemption is permitted during these register manipulations, Task B may preempt Task A after the Packet A data has been queued but before the transmit is begun. Then Task B calls the sockets-layer function, which calls the TCP-layer function, which calls the IP-layer function, which calls the Ethernet driver, which queues and transmits Packet B. When control of the CPU returns to Task A, it finally requests its transmission. Depending on the design of the Ethernet controller chip, this may either retransmit Packet B or generate an error. Either way, Packet A’s data is lost and does not go out onto the network.
In order for the functions of this Ethernet driver to be callable from multiple RTOS tasks (near-) simultaneously, those functions must be made reentrant. If each function uses only stack variables, there is nothing to do; each RTOS task has its own private stack. But drivers and some other functions will be non-reentrant unless carefully designed.
The key to making functions reentrant is to suspend preemption around all accesses of peripheral registers, global variables (including static local variables), persistent heap objects, and shared memory areas. This can be done either by disabling one or more interrupts or by acquiring and releasing a mutex.
Best Practice: Create and hide a mutex within each library or driver module that is not intrinsically reentrant. Make acquisition of this mutex a pre-condition for the manipulation of any persistent data or shared registers used within the module as a whole. For example, the same mutex may be used to prevent race conditions involving both the Ethernet controller registers and a global (or static local) packet counter. All functions in the module that access this data must follow the protocol to acquire the mutex before manipulating these objects.
Beware that non-reentrant functions may come into your code base as part of third party middleware, legacy code, or device drivers. Disturbingly, non-reentrant functions may even be part of the standard C or C++ library provided with your compiler. For example, if you are using the GNU compiler to build RTOS-based applications, you should be using the reentrant “newlib” standard C library rather than the default.
#4: Priority Inversion
When two or more tasks coordinate their work through, or otherwise share, a singleton resource, a range of nasty things can go wrong. Above, I discuss two common problems in task-sharing scenarios: race conditions and non-reentrant functions. Now let’s look at priority inversion, which can be equally difficult to reproduce and debug.
The problem of priority inversion stems from using an operating system with fixed relative task priorities. In such a system, the programmer must assign each task its priority. The scheduler inside the RTOS provides a guarantee that the highest-priority task gets the CPU at all times. To do so, the scheduler may preempt a lower-priority task in mid-execution. But sometimes events outside the scheduler’s control can prevent the highest-priority task from running when it should, resulting in a missed critical deadline or a system failure.
At least three tasks are required for a priority inversion to occur: the pair of highest and lowest relative priority must share a resource, say, by a mutex, and the third must have the priority between the other two.
The figure below displays this scenario well. First, the low-priority task acquires the shared resource (time t1). After the high-priority task preempts low, it next tries but fails to acquire their shared resource (time t2), and control of the CPU returns back to low. Finally, the medium priority task—which has no interest at all in the resource shared by low and high—preempts low (time t3). Now, the priorities are inverted: medium is allowed to use the CPU for as long as it wants, while high waits for low. There could even be multiple medium priority tasks.
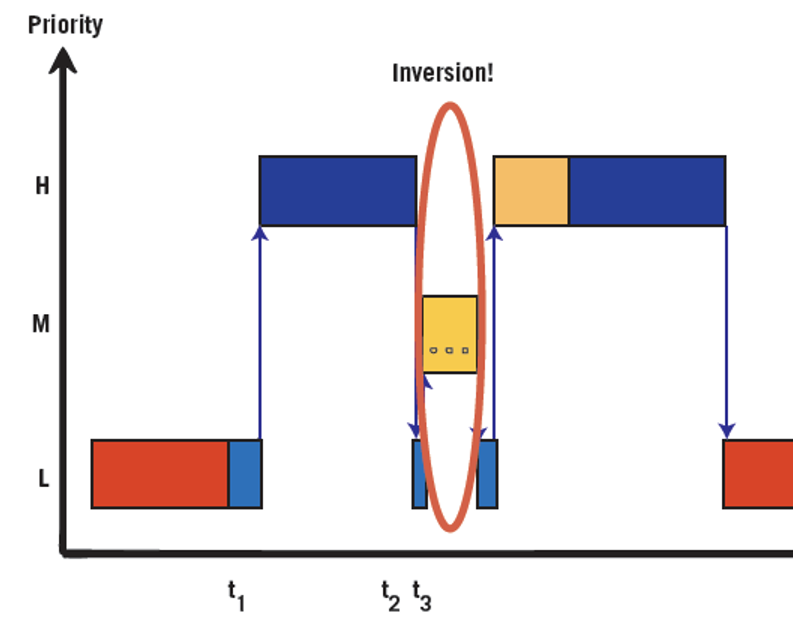
Best Practice: An easy three-step fix will eliminate priority inversions from your system. First, choose an RTOS that includes a priority-inversion work-around in its mutex API, typically called a priority inheritance protocol or priority ceiling emulation. Secondly, only use the mutex API to protect shared resources within real-time software. Third, take the additional execution time into account when performing the analysis to prove that all deadlines will be met.
#5: Memory Leak
Eventually, systems that leak even small amounts of memory will run out of free space. Often, legitimate memory areas get overwritten, and the failure isn’t registered until later.
Memory leaks are a problem of ownership management. Objects allocated from the heap always have a creator, such as a task that calls malloc() and passes the resulting pointer on to another task via message queue or inserts the new buffer into a meta heap object such as a linked list. But does each allocated object have a designated destroyer? Which other task is responsible and how does it know that every other task is finished with the buffer?
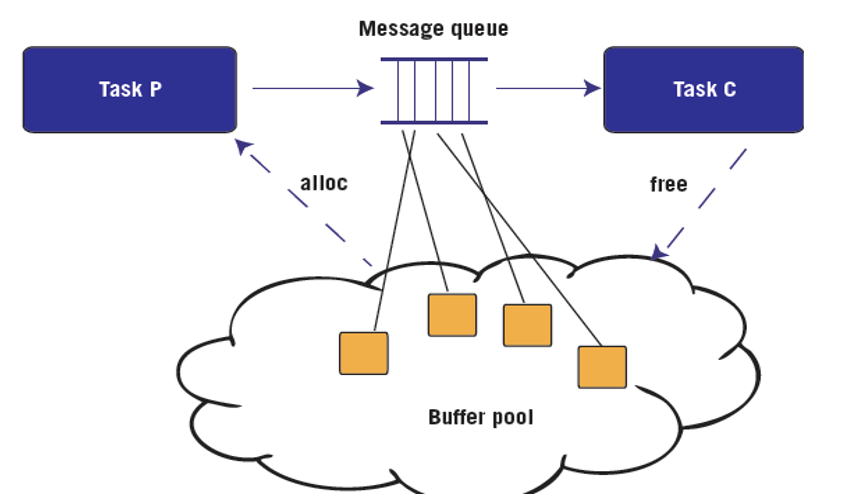
Best Practice: A simple way to avoid memory leaks is to clearly define the ownership pattern or lifetime of each type of heap-allocated object. The figure above shows one common ownership pattern involving buffers that are allocated by a producer task (P), sent through a message queue, and later destroyed by a consumer task (C).
In addition to avoiding memory leaks, the design pattern shown in Figure 3 can be used to ensure against “out of memory” errors, in which there are no buffers available in the buffer pool when the producer task attempts an allocation. The technique is to (1) create a dedicated buffer pool for that type of allocation, say, of 17-byte buffers; (2) use queuing theory to appropriately size the message queue to ensure against a full queue; and (3) size the buffer pool so there is initially one free buffer for each consumer, each producer, plus each slot in the message queue.
Conclusion
Given the potential cost of finding bugs and the potential liability of undiscovered bugs, your best defense is prevention. The best practices described here will not only help you prevent these bugs in the first place, but will also make it easier to detect and eliminate bugs that do appear in your IoT device firmware design.
Michael Barr is the co-founder and Chief Technical Officer of Barr Group. He is the former adjunct professor of electrical and computer engineering with over a decade of software design and implementation experience. Internationally recognized as an expert in the field of embedded software process and architecture, Barr has been admitted as a testifying expert witness in U.S. and Canadian court cases involving issues of reverse engineering (including DMCA), interception of encrypted signals (Federal Communications Act), patent infringement, theft of copyrighted source code (including trade secrets issues), and product liability.
Barr is also the author of three books and more than sixty articles and papers on embedded systems. For three and a half years Barr served as editor-in-chief of Embedded Systems Programming magazine. In addition, Barr is a member of the advisory board and a track chair for the Embedded Systems Conference. Software he wrote continues to power millions of products. Barr holds B.S. and M.S. degrees in electrical engineering and has lectured in the Department of Electrical and Computer Engineering at the University of Maryland, from which he also earned an MBA.
Barr Group
www.barrgroup.com
Leave a Reply