By Vincent Haché, Technical Staff, FW Engineering, Microchip Technology
Big data analytics and AI model training present huge challenges for processing with GPUs. Their datasets can be hundreds of terabytes requiring millions of file access on an equal number of files. As the pace of this data onslaught continues, it has become obvious that conventional ways of transferring data from a CPU to GPUs and storage is insufficient, severely restricting the ability of GPUs to utilize their enormous resources efficiently. Several advances have been made to solve the resulting bottlenecks, including Nvidia’s GPUDirect Storage, but exploiting its full capabilities is hindered by PCIe.
Even in its latest iteration, PCIe Gen 4 retains the same basic tree-based hierarchy it has used since its inception. This effectively makes it complex, especially in the case of multi-host, multi-switch configurations. Fortunately, it is possible to bypass these limitations through the use of PCIe fabric and the benefits of SR-IOV-enabled storage devices with dynamic switch partitioning. Using this approach, a pool of GPUs and NVMe SSDs can be shared among multiple hosts while still supporting the host’s standard system drivers.
Defining the conundrum
Traditionally, data is moved into the host’s memory and “bounced” out to the GPU relying on an area in CPU system memory called a bounce buffer. In the bounce buffer, multiple copies of the data are created before being transferred to the GPU. This additional copy is undesirable but unavoidable as it a fundamental CPU process. The considerable data movement across these paths introduces latency, reduces overall GPU processing performance, and uses many CPU cycles in the host. Systems with a large amount of memory and intense I/O activity can create many bounce buffers that result in challenging shortage problems.
As a result, the massive number-crunching ability of the GPU is underutilized as it waits for incoming data. This bottleneck has become the most time-consuming operation in the processing data flow. For an increasing number of applications, this situation is unacceptable. For example, high round-trip latency can allow a fraudulent financial transaction to occur unimpeded, or it can negatively impact the time required to train an AI model. Not surprisingly, removing this bottleneck is one of the primary goals within high-performance computing and AI.
It is also why Nvidia created GPU Direct Storage, currently nearing general release, and the latest in the company’s efforts to optimize GPU performance in the higher echelons of AI training and similar intensive workloads. Before this, the company introduced GPU Direct RDMA designed to increase bandwidth and reduce latency by minimizing copies in the bounce buffer. It also provides direct memory access closer to the storage that passes data to and from GPU memory. Now, GPUDirect Storage allows GPUs to communicate directly with NVMe storage, and while its control path uses the CPU’s file system, it does not need to access the host CPU and memory.
PCIe 4.0: big improvements with one exception
The release of the PCI Express Base Specification Revision 4.0 Version 1.0 in 2017 offers major improvements over its Gen 3 predecessor, such as doubling throughput per lane from 1 Gb/s to 2 Gb/s and increasing speed to 16 GT/s. However, PCIe still retains the base standard’s rigid tree-based hierarchy in which there is one root complex per domain.
The hierarchy fundamentally remains the same, although the previous bus-based topology of PCI and PCI-X has been replaced by point-to-point connectivity that employs switches for distribution. PCIe Gen4 remains focused on efficiently interconnecting single-root configurations in which there is a one-to-one relationship between root and an endpoint. So, while Gen 4 has much to recommend it, the protocol makes it necessary to work around its family hierarchy to achieve the benefits of GPU Direct and PCIe Gen 4 in a multi-switch, multi-host system.
Figure 1 illustrates the problem. With its single root port, a PCIe-compliant system requires the first host (Host 1) to have a dedicated downstream port in Switch 1 connected to a dedicated upstream port in Switch 2. A dedicated downstream port is required in Switch 2 that is connected to a dedicated upstream port in Switch 3, and so on.
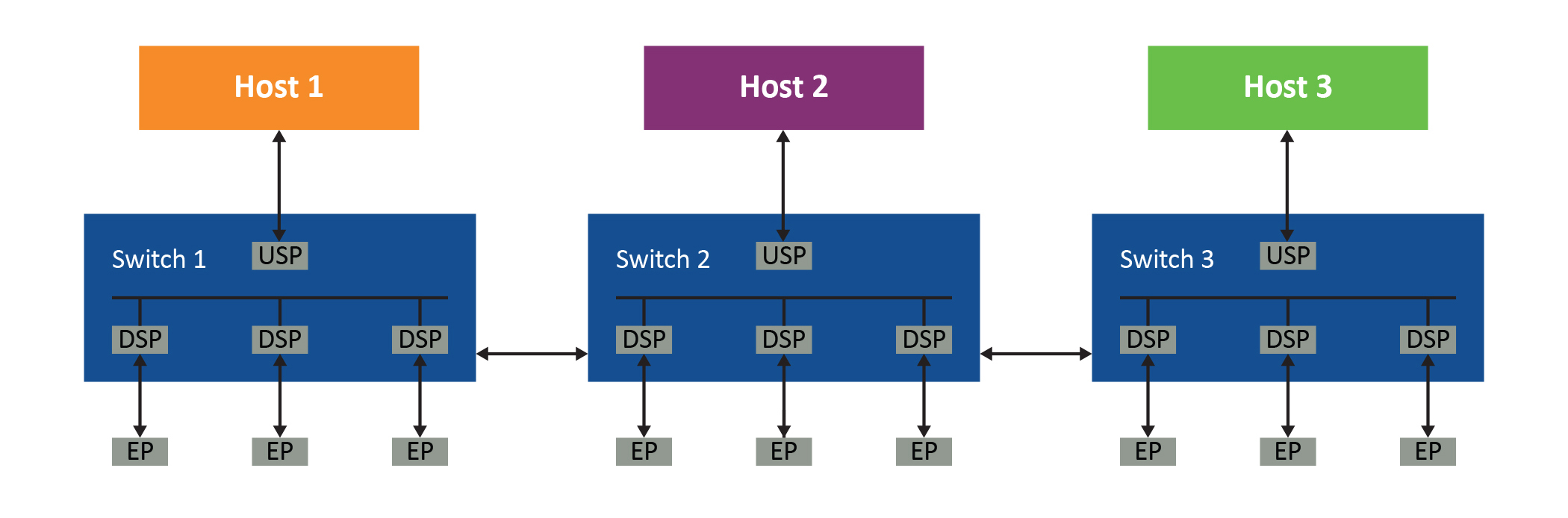
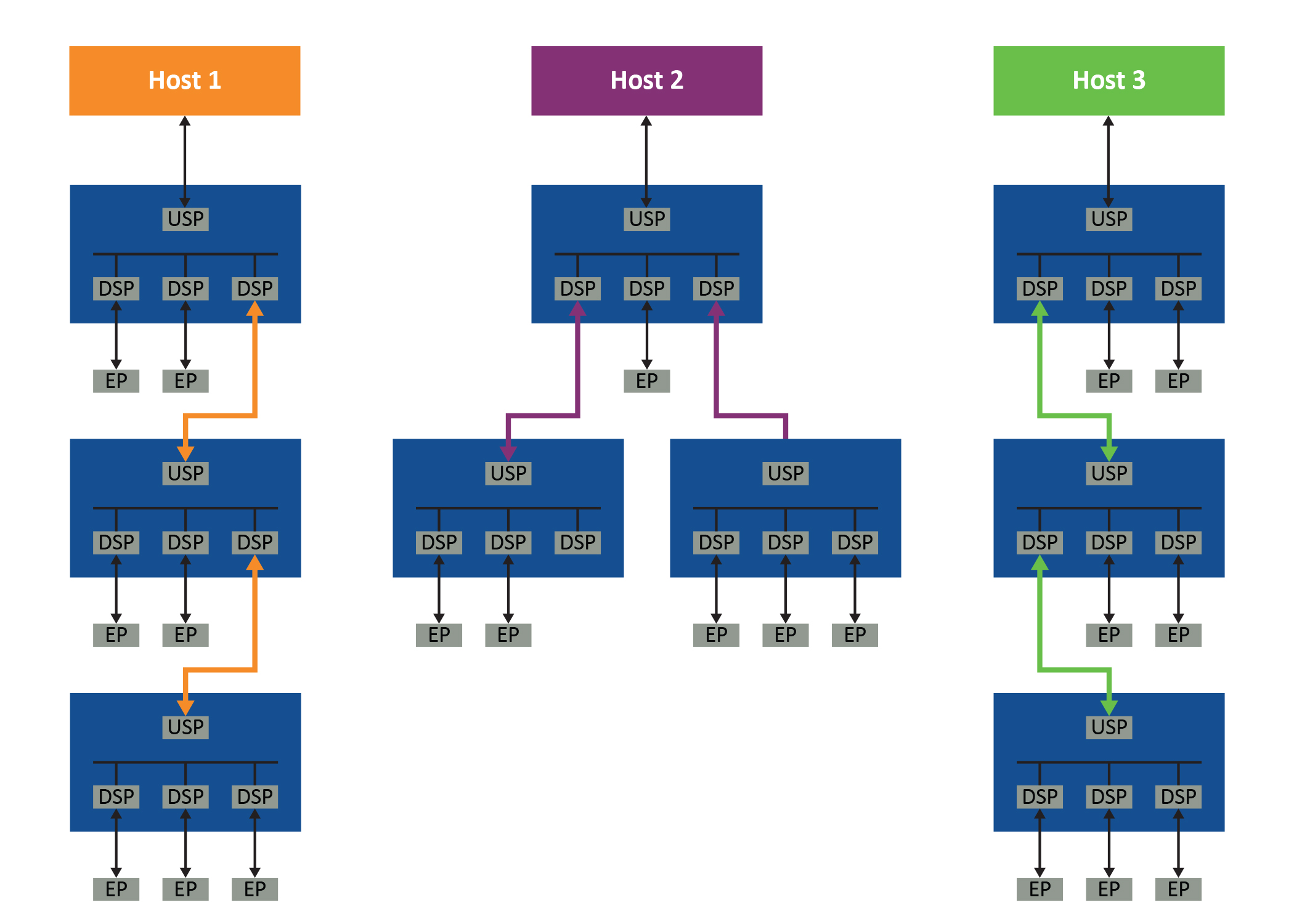
So, even the simplest PCIe tree structure-based system requires links between each switch that is dedicated to each host’s PCIe topology. There is no way to share these links between multiple hosts, which quickly results in the system becoming complicated and extremely inefficient. This is especially true in a large system employing many GPUs, storage devices and their controllers, and switches.
PCIe I/O virtualization provides a way to minimize this problem as it makes one physical device appear as multiple virtual devices. These virtual devices are completely independent and allow multiple operating systems to run simultaneously while natively sharing physical PCIe devices such as SSDs.
Single-root I/O virtualization (SR-IOV) allows an I/O resource to be shared between multiple system images on a single host. In contrast, multi-root I/O virtualization (MR-IOV) allows these resources to be shared between multiple system images on multiple hosts. SR-IOV works very well in multicore, multi-socket systems as it reduces the number of required I/O devices of the same type and allows more of them to be installed in a system if required. Consequently, SR-IOV is employed widely in many storage, and other types of devices support it.
In contrast, MR-IOV is comparatively complicated and still allows unused PCIe devices to be stranded in the single host domain in which they reside. For example, if Host 1 has consumed all its compute resources while Hosts 2 and 3 have not, logic dictates that Host 1 should be able to access them. However, this cannot occur from a practical standpoint because they’re outside Host 1’s domain, so they become stranded and unused. Non-transparent bridging (NTB) is a potential solution to this problem but is complex, requiring non-standard drivers and software for each type of shared PCIe device. A much better approach is to use the PCIe fabric that lets a standard PCIe topology accommodate multiple hosts that can access every endpoint.
The PCIe fabric solution
By combining the benefits of SR-IOV-enabled storage devices along with dynamic partitioning, it’s possible to create a low-latency, high-speed fabric approach to this problem. It allows a pool of GPUs and NVMe SSDs to be shared among multiple hosts while still supporting the host’s standard system drivers. The PCIe fabric routes peer-to-peer transfers directly across the fabric, which allows optimal routing, decreases root port congestion and eliminates CPU performance bottlenecks (Figure 3).
This approach can be implemented using a PCIe fabric switch such as Microchip’s PM42036 PAX 36xG4 Gen 4 in two discrete but transparently interoperable domains: a fabric domain containing all endpoints, and fabric links and host domains dedicated to each host (Figure 3). The hosts are kept in separate virtual domains via the PAX switch firmware that runs on an embedded CPU, so the switch will always appear as a standard single-layer PCIe device with direct-attached endpoints, regardless of where those endpoints appear in the fabric.

Transactions from the host domains are translated to IDs and addresses in the fabric domain and vice versa with the non-hierarchical routing of traffic in the fabric domain. This allows the fabric links connecting the switches and endpoints shared by all hosts in the system. The switch firmware intercepts all configuration plane traffic from the host, including the PCIe enumeration process. It virtualizes a simple, PCIe specification-compliant switch with a configurable number of downstream ports.
Unused GPUs in other host domains are no longer stranded because they are dynamically assigned based on the needs of each host. Peer-to-peer traffic is supported within the fabric, which allows it to accommodate machine learning applications. Standard drivers can be used because capabilities are presented to each host in a PCIe specification-compliant manner.
Demonstrating performance
The system shown in Figure 4 illustrates how two hosts can use their virtual functions independently, fully exploiting the benefits of GPUDirect Storage by removing the CPU from the process, eliminating the bottlenecks caused by its inherent bounce buffer problems, and allowing it to perform the functions for which it is best suited. The hosts are presented with a very simple PCIe tree that consists of only the devices that are bound to it.
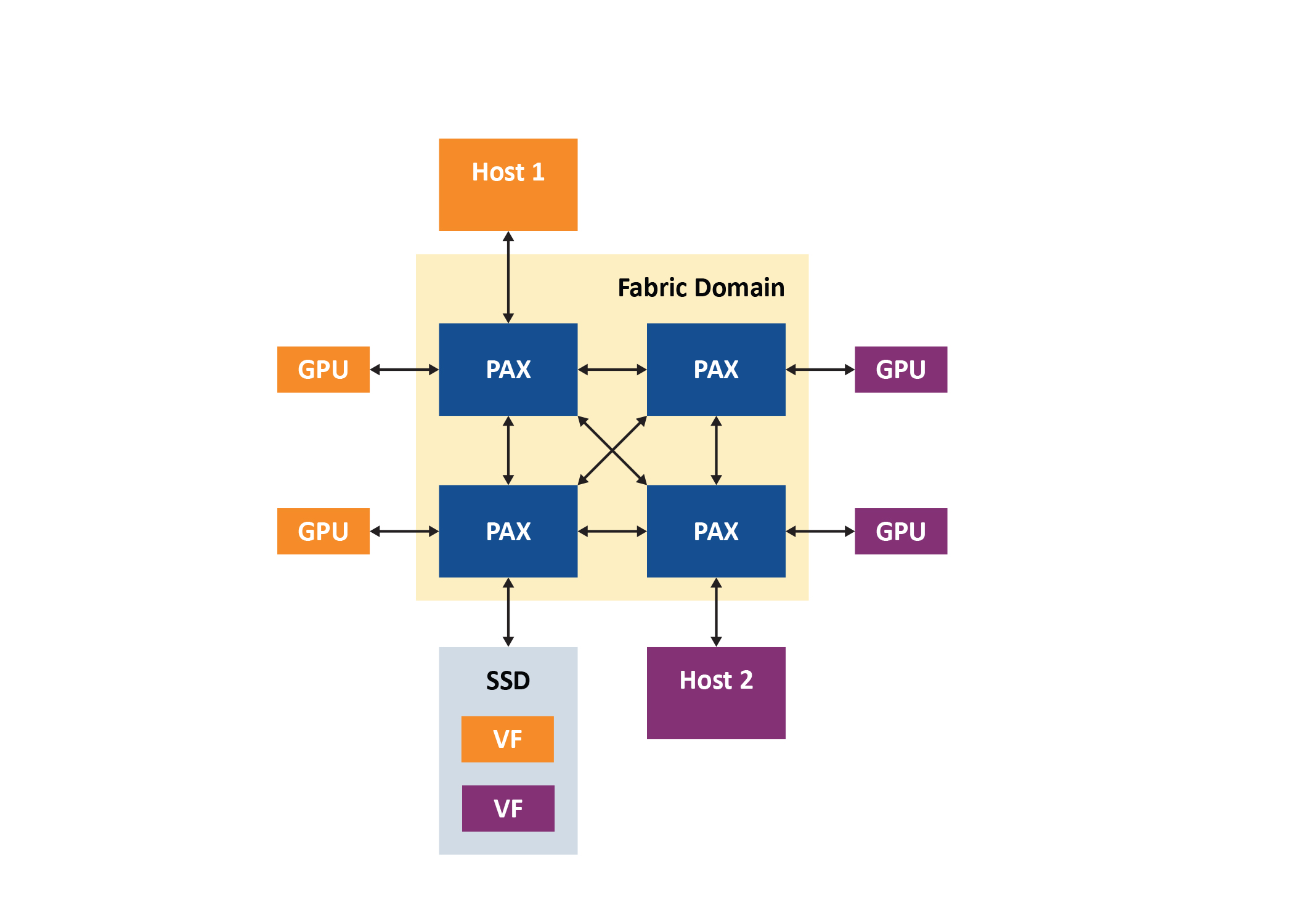
In the system, Host 1 has a Windows OS, and Host 2 is Linux. There are PAX PCIe fabric switches, four Nvidia M40 GPGPUs, and a single Samsung NVMe SSD with SR-IOV support. The hosts run traffic representative of actual machine learning workloads, including Nvidia’s CUDA peer-to-peer traffic benchmarking utility and training the cifar10 image classification TensorFlow model. The embedded switch firmware handles the low-level configuration and management of the switch, and the system is managed by Microchip’s ChipLink debug and diagnostics utility.
After the Windows host is booted, the PAX fabric manager shows all devices discovered in the fabric with the GPUs bound to the Windows host and appearing in Windows device manager as standard devices. The host views the switch as a simple physical PCIe device with a configurable number of downstream ports. As the complexities of the fabric are intentionally obscured from the host, all four GPUs appear to be directly connected to the virtual switch. CUDA is then initialized and discovers the four GPUs.
Using this configuration, a peer-to-peer bandwidth test shows unidirectional transfers occurring at 12.8 GB/s and bidirectional transfers at 24.9 GB/s. These transfers go directly across the PCIe fabric without passing through the host. The TensorFlow model is run to train a Cifar10 image classification algorithm with the workload distributed across all four GPUs. After completion, two GPUs can be unbound from the host and released back into the fabric pool. As the fabric switch simulates hot removal, the two unused GPUs are available for use in other workloads.
The Linux host, like its Windows counterpart, sees a simple PCIe switch without the need for custom drivers, and after CUDA discovers the GPUs, peer-to-peer transfers can be run on the Linux host. Performance is similar to what was achieved with the Windows host, as seen in Table 1.
Now that both systems are running, SR-IOV virtual functions for the SSD can be attached to the Windows host. Once again, the PAX switches appear as standard physical NVM devices, which allows the host to use a standard NVMe driver. The same steps are then performed on the Linux host, and a new NVMe device appears in the block device list.
This demonstration uses a single SSD rather than multiple storage devices, but the same basic approach can be employed in a RAID configuration. In this case, the speed and latency of the RAID controller becomes extremely important owing to the higher speeds that can be achieved. Currently, the only RAID controller with the ability to accommodate a transfer rate of 24.9 GB/s is Microchip’s SmartROC 3200 RAID-on-chip controller. It has very low latency and offers up 16 lanes of PCIe Gen 4 to the host and is backward compatible with PCIe Gen 2. The device’s driver has been integrated within the interface of Nvidia’s software library as well.
Summary
No matter the configuration in which the approach described in this article is used, all virtual PCIe switch and all dynamic assignment operations are presented to the host as fully PCIe specification compliant. This is a major benefit as there is no need for custom drivers. In addition, the switch firmware provides a simple management interface so the PCIe fabric can be configured and managed by an inexpensive external processor. Device peer-to-peer transactions are enabled by default and require no additional configuration or management from an external fabric manager.
In short, the PCIe switch fabric is a practical means of exploiting the ability of GPU Direct Storage to solve not only the bounce buffer problem while increasing achievable performance of 24.9 GB/s as well. The use of dynamic switch partitioning and SR-IOV sharing techniques allows the GPUs and NVMe resources to be dynamically allocated to any host in a multi-host system in real-time to meet the varying demands of machine learning workloads.
Leave a Reply