
There are several types of neural networks (NNs). Recurrent NNs (RNNs) can “remember” data and use past information for inferences. This article compares recurrent NNs with feed-forward NNs (FFNNs) that can’t remember, then digs into the concept of backpropagation through time (BPTT) and closes by looking at long short-term memory (LSTM) RNNs.
RNNs and FFNNs handle information in different ways. In a FFNN, information moves straight from the input layer to the hidden layers and to the output layer. As a result, FFNNs have no memory of previous inputs and are not useful for predicting the future. The only use of past information in an FFNN is for training. Once the network is trained, past information is not considered. FFNNs are used for classification and recognition tasks.
In an RNN, information moves through a loop. RNNs consider both the current input and what has been learned from previous inputs. A fixed weight parameter flows through the layers of a FFNN. In an RNN, deep learning occurs because the weight parameters depend on the results of earlier calculations. In an RNN, the hidden layer acts as the “memory.” RNNs are used for deep learning applications like natural language processing, path prediction from moving objects, financial predictions, and weather forecasting.
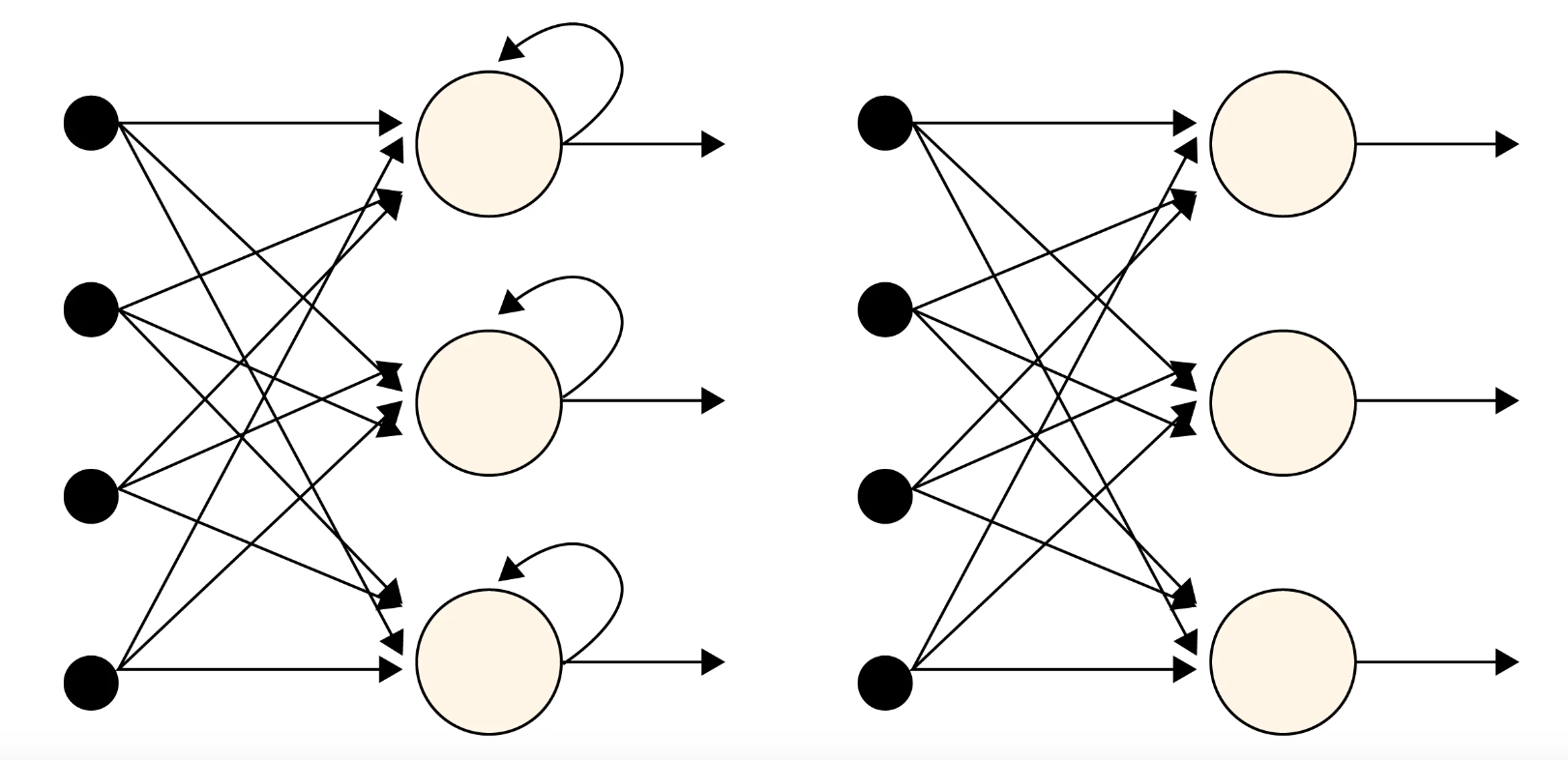
There are three types of weights used in an RNN. These include the input weights and the hidden-to-output weights, which are like the weights in an FFNN. However, an RNN adds a third type: the weights used for hidden-to-hidden recurrent connections that loop back toward the input (Figure 1).
Backpropagation through time
Backpropagation (BP) is a foundational algorithm in machine learning (ML). In an NN, forward propagation is used for information traveling from the input to the output and then checking for any error. Backpropagation is used during training to find the gradient of an error function relative to the network’s weights.
A backpropagation algorithm steps backward through the layers to find the partial derivative of the errors relative to the weights. Those derivatives are then used by an algorithm called gradient descent that iteratively minimizes the errors. NN training is based on the process of adjusting the weights up or down using the combination of backpropagation and gradient descent that changes the weights as needed to decrease the error.
An RNN can be thought of as a sequence of NNs that are trained sequentially using backpropagation. In a fully recurrent neural network FRNN, the outputs of all neurons are connected to the inputs of all neurons. An FRNN is the most generalized RNN, and various other types of RNN can be derived by setting some of the connection weights to zero to indicate the lack of connection between corresponding neurons.
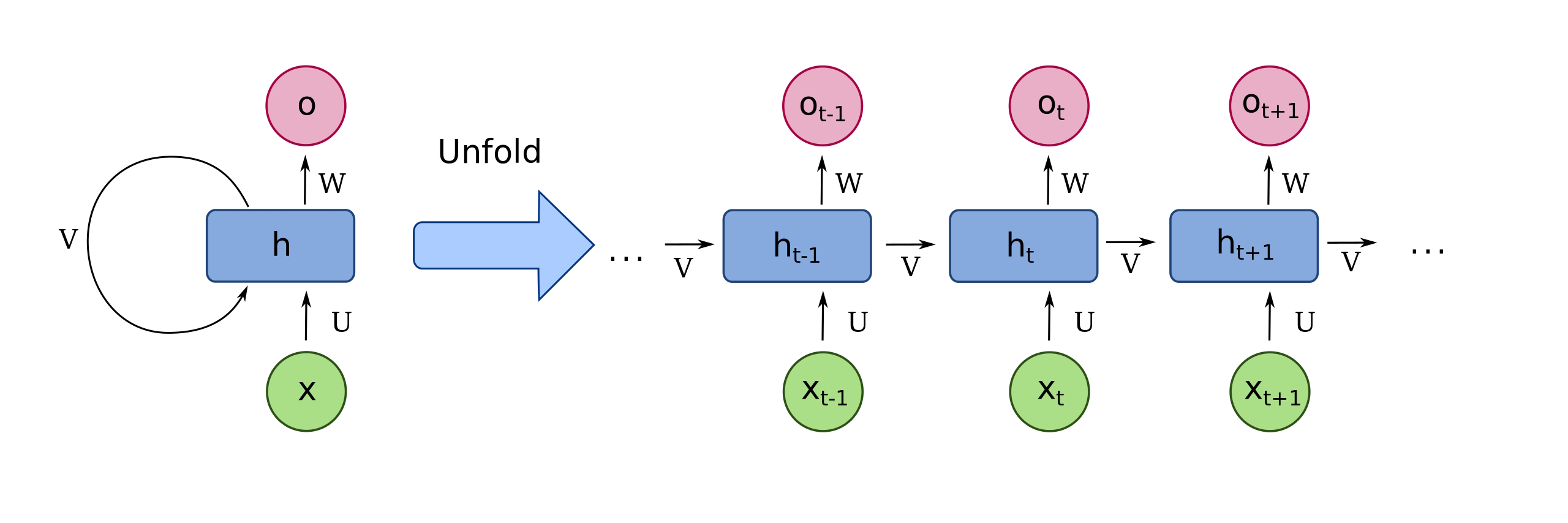
Figure 2 illustrates the implementation of backpropagation in an RNN. The left cell shows the basic input, hidden, and output weights of U, V, and W, respectively. On the right, it’s “unfolded” to show the time progression of weight changes that occur using backpropagation and gradient descent.
Long short-term memory
An LSTM is a type of RNN that provides a short-term memory that can last thousands of timesteps. An LSTM-RRN cell can process data sequentially and update the weights of its hidden state through time.
Theoretically, conventional RNNs can track long-term dependencies in the input sequence for an arbitrary length of time. In practice, however, when training a conventional RNN using backpropagation, the long-term gradients tend to be zero, which stops any learning. LSTM-RRN units are designed to fix the vanishing gradient problem by allowing gradients to flow with minimal attenuation. However, if not properly designed, LSTM can experience exploding gradients and increasing errors.
In an LSTM-RRN, an additional learning algorithm is added that learns when to remember and when to forget specific types of information. In addition to learning how to perform a specific function like natural language processing, an LSTM-RRN learns what information to remember to improve its long-term performance.
Summary
RRNs include a third weight that’s not found on FFNNs for hidden-to-hidden layer recurrent connections that loop back toward the input. Those hidden-to-hidden weights enable RRNs to learn from their mistakes and modify the weights during training. The techniques used during training are called backpropagation and gradient descent algorithms. In practical implementations, backpropagation can result in a vanishing gradient and an end to learning. LSTM-RRNs have been developed to solve the vanishing gradient problem and enable continuous learning.
References
A Complete Guide to Recurrent Neural Networks (RNNs), Built in
Introduction to Recurrent Neural Network (RNN), Scalar
Recurrent neural network, Wikipedia
What are recurrent neural networks?, IBM
What Is RNN?, AWS


Leave a Reply