Traditionally a cache is a safe place to keep things hidden until you can retrieve them. However, a cache within computer terminology is any storage that is managed to take advantage of location for rapid access. Cache is local memory that exists in the data path between the processor and main memory. A cache will hold a collection of data that has been recently referenced and has a high probability of being requested by the processor again. Nearly every modern general-use processor, from desktop computers to servers and embedded processors, makes use of a cache. Cache is local to the processor, i.e., it is located on the same chip as the processor. Cache is used to speed up processing because off-chip memory takes more processor cycles to access than does cache. But in the race for ever-faster computing, a cache isn’t as simple as a memory bank for stashing data the processor might need next.
In order to understand cache better, it’s important to understand the term “memory hierarchy.” Memory hierarchy differentiates computing storage based on the amount of time it takes to interact with a type of storage.
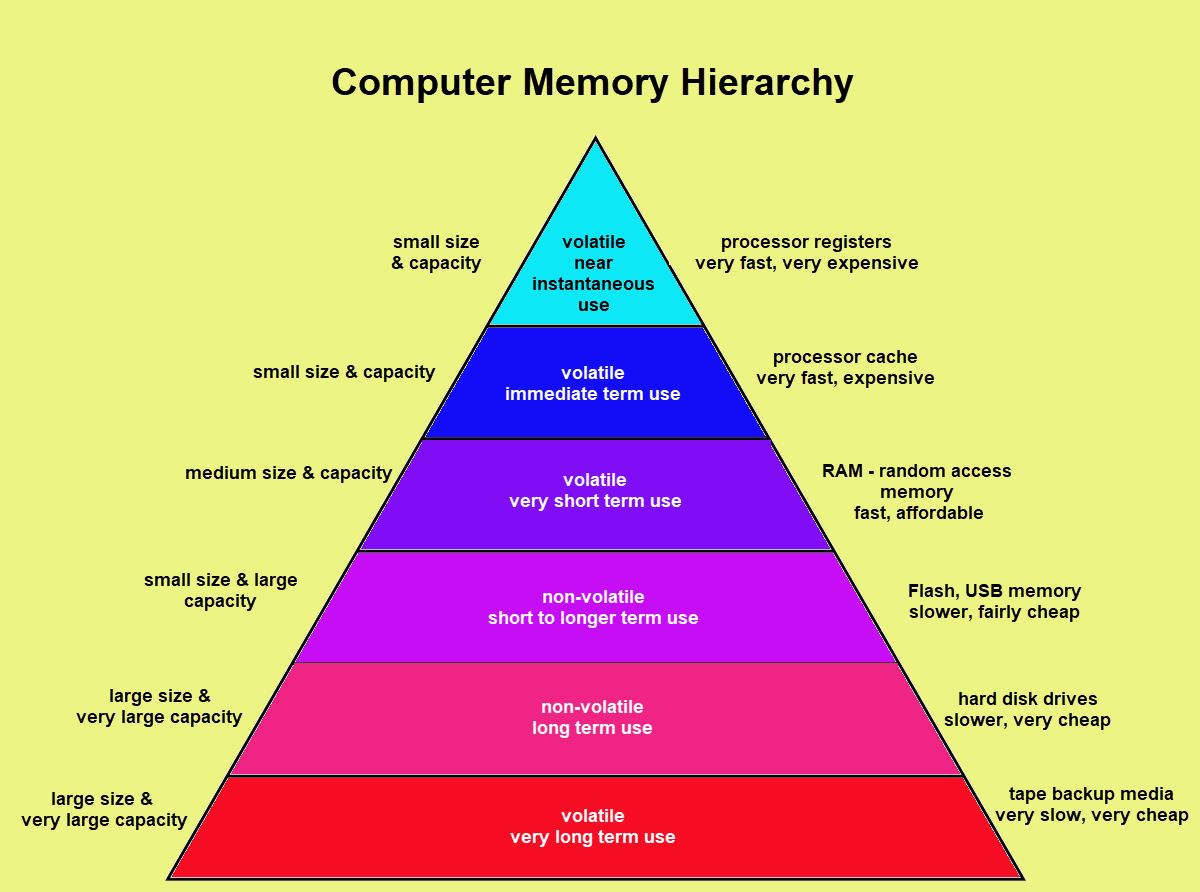
A direct-mapped cache maps each memory location to one location in the cache. Each cache memory is tagged with address information that corresponds to the address of the data in main memory. If a cache location is not loaded with good data, perhaps just after boot up, it will have a “valid bit” that shows whether or not the cache entry contains a valid (working) address. A valid bit is a field in the tables of the memory hierarchy that indicates that the associated block in the hierarchy contains valid data. Therefore, a cache location may be occupied with nothing or junk, but the valid bit shows whether or not the cache can be overwritten with the valid data. Reading from a cache is faster than writing to the cache, as with any type of memory, because reads do not change the contents of a memory location. Very large caches can create their own problem of increased latency, defeating the purpose of the cache to begin with. To defeat this issue, caches can have several levels, called a multi-level cache. In a multi-level cache, the most expedient data is stored in the cache at the top of the cache hierarchy, lower-level data, in terms of relevancy to the processor’s immediate task, is stored in the second level, and so forth. It’s common for caches to have up to four levels (i.e., an L4 cache), but of course, more or fewer levels can be used. The highest level of cache, before accessing external memory lower on the hierarchy, is called the last level cache (LLC). A question arises about what happens with caches for multi-core chips. Multi-core chips can have a common shared cache for all cores where global variables might be stored at the highest level (L3 or L4, for example) but a dedicated L1 cache is local to each processor since sharing an L1 cache across several processor cores would just add to the complexity and latency.
What happens if the cache does not have the required data? When the cache does not include required data in cache memory, it’s termed a ”cache miss,” and the data must be fetched from lower down on the hierarchy, perhaps from a much slower hard disk drive, which slows things down. If the processor encounters a cache miss, extra steps are required. If everything was going along swimmingly and the processor has been serviced by a full pipeline, the cache miss creates a stall in the pipeline that’s servicing the processor, and the processor experiences a stall. Whereas a processor interrupt requires all working memory registers to be saved while the processor executes a new task, the cache miss simply freezes everything, waiting for the memory fetch. Some processors get around a cache miss by processing out of order execution (OoOE). With OoOE, instructions are executed in order of data availability rather than in the order established by the software program, thus avoiding idling of the processor.
Caching data is faster because of it’s physical location and the physical nature of the media used for a cache. However, caches also employ predictive mechanisms to keep data that is most likely to be needed in the faster cache memory, versus fetching data from farther away and slower memory media. Caches are generally right 95% of the time, and yet when data is not present in the cache, the option to retrieve the data from lower down the memory hierarchy is always present. However, the prediction miss rate gets higher as larger blocks of data are required. In other words, if a cache is too small to handle the average block of data that’s require to complete a set of related tasks, then the benefits of having a cache reduce, and the processor (computer) gets slower. In the case of a desktop computer, one can increase the size of the cache manually, but this is more difficult in an embedded processor since embedded processors are typically intended to operate without human intervention. Some elaborate schemes have been created to regain cache performance, but are something of a bandage to the problem.
These methods are called early restart and requested word first (or critical word first), and are, in simple terms, involve resuming execution before the transfer process is complete and depend upon favorable race conditions between the processor resumption and completion of memory fetch. In this case, if memory fetch is too slow to complete, then the processor has to wait, defeating the purpose of the cache.
The complexities of the cache are something which will be executed before the transfer process is complete so just go through the part.