Neural network software can be difficult to debug. One reason: It functions only vaguely in the way it has been explained to the general public.
Leland Teschler, Executive Editor
CRACK open an autonomous-driving vehicle and you will find neural networks taught to recognize objects such as pedestrians, road signs, and other vehicles. Recent accidents involving autonomous and semi-autonomous vehicles have brought up questions about these deep learning networks. One factor that sometimes puzzles outsiders is how to debug a neural net that gets the wrong answer about images it sees. The topic can bewilder non-practitioners because, to human eyes, the data a neural net stores may bear no obvious resemblance to images it knows about.
It can be useful to review how neural nets used in AV technology actually recognize images because there are widespread misconceptions about the recognition process.
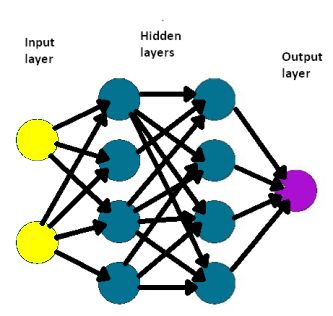
Artificial neural networks are usually depicted as columns of artificial “neurons” – usually dubbed a layer — connected to other columns of neurons. There is an input layer of neurons and an output layer, as well as several intervening or hidden layers between the input and output layers. Input neurons connect to each of the neurons in the next hidden layer. Neurons in a hidden layer, in turn, connect to the neurons both in the layer before and after it. Finally, neurons of the output layer receive connections from the last hidden layer and produce an output pattern.
The connections between neurons are weighted. That is, the value of an input neuron is multiplied by a specific weighting factor and added to the neuron in the inner layer to which it connects. Weights can be positive and negative, and the higher the weight, the more the influence. If the sum of the inputs to a given neuron exceeds a certain threshold value, the neuron fires and triggers inputs to the neurons to which it connects.
Neural nets learn things by comparing the output the network produces to what it was supposed to produce. The difference in values is used to change the weights of the connections between neurons in the network, starting at the output neurons going back through progressive layers of hidden neurons. The process is called backpropagation. The idea is that eventually, backpropagation reduces the difference between actual and intended outputs to a point where they coincide.
Most explanations of neural nets use the model of columns of neurons and connections between them. In actuality, the physical realization of neural nets looks nothing like this model. Neural nets run on ordinary processors. The “neurons” are just locations in a memory. So are the connections between the neurons and the weights they represent. An algorithm computes the neuron values from the weights. For the sake of computation speed, neural nets may employ computer architectures that are highly parallel, so values get calculated as quickly as possible. But these architectures look nothing like the columns of neurons and connections that characterize neural net explanations.
Neural network technology has progressed to the point where open-source software for constructing neural nets has become available. Some of the more well-known packages include Neuroph, a Java neural network framework; Weka, a collection of machine learning algorithms from the University of Waikato in New Zealand; Eclipse Deeplearning4j, a deep-learning library written for Java and Scala; and Caffe, a deep learning framework developed by Berkeley AI research.
However, it is unlikely that any autonomous systems use open-source frameworks for their neural nets. The more typical approach is probably similar to that employed by Affectiva, an M.I.T. Media Lab spin-off that fields a neural net for measuring the emotional and cognitive states of vehicle driver and passengers, based on inputs from a camera and microphones. As explained by Affectiva product manager Abdo Mahmoud, “We started our neural net from scratch because we want to run a deep neural net using extremely low computational power. Open-source neural nets usually come from academia where computational power isn’t a constraint”.
The purpose of Affectiva’s neural net is to gage the mood and demeanor of both the driver and passengers in real time. Outputs of the neural net would then be used to detect distracted drivers or bored passengers. The result might be an audible warning for the driver or suggestions to passengers for video or music from a virtual assistant. The Affectiva neural net typically runs on the car’s infotainment processor and is written in C++.
Mahmoud says the program designers used numerous methods to minimize the errors that the program might make in gaging moods. Their main technique was to measure performance across a wide variety of use cases. Program designers included situations where occupants sported head scarfs, sun glasses, facial hair, and other impediments obscuring their facial expressions. Designers also conducted specific experiments to elicit emotions and measure the program’s performance on those use cases.

Affectiva designers don’t use just one image to categorize emotions. The system builds confidence by considering a sequence of images. A good example is in differentiating a person speaking from one yawning. The system’s confidence in telling one from another grows with succeeding images.
Thus the Affectiva neural net doesn’t respond to moment-by-moment changes in occupant expressions, Mahmoud explains. By responding only to significant emotional changes in facial expressions, the system greatly reduces false positives.
What neural nets really see
When authors try to explain how neural nets recognize images, they often do so by taking a simple example, such as recognizing the letter “O.” They then suggest that the neural net separates the letter into sections such as loops, edges, and straight lines – each divined by one of the inner layers of neurons — then deduces the letter O from the position of these features.

Unfortunately, this example is strictly an analogy to what transpires when a neural net examines an object. In reality, the weight matrix for each neuron in the net would most likely look like random noise with no recognizable features evident. The reason for the random-looking nature of the weight matrix is that it is only in combination with other inner-layer neurons that features useful for recognition emerge. Examining single inner neurons doesn’t provide any insight into what features have been discerned.
The inability to judge what happens at a given neuron is problematic when it comes to debugging. It’s not possible to debug a neural net simply by looking at the weight matrix of its individual neurons. This is why there is concern about neural networks that fail to notice important details like a pedestrian crossing in front of an autonomous vehicle.
In fact, the debugging process for a neural network tends to probe general attributes of the network rather than starting with a specific problem and tracking back to find the source. For example, many troubleshooting procedures for neural networks include checking the training data for errors, checking the neural network’s behavior with a small subset of the original training data, removing internal layers to see what happens, using a different distribution of weights for the initial model, checking whether the summation of errors changes a lot over long periods, and detecting whether activation functions have saturated and prevented the network from further learning.
The point to note about this process is that the debugging procedure is largely the same for any number of situations where the network gives a wrong output. It is not specific to a particular wrong output. And if the network suddenly begins generating the correct output after it’s been debugged, it may not be possible to understand exactly what change brought the desired output.




Leave a Reply