
By Daniel Joseph Barry, VP Strategy and Market Development, Napatech
Many of the latest innovations in cloud, enterprise, and telecom networks are predicated on the assumption that the power of server CPUs will continue to grow in line with Moore’s Law. This law predicts that the number of transistors per square inch will double every 18 months, thereby increasing the processing power delivered per square inch. This prediction has held for so long that many of us take it for granted. Unfortunately, it is now becoming increasingly clear that the growth in server CPU processing power, on which we have all come to rely, will not continue. So, what do we do now?
The Death of Moore’s Law
While the slowdown in CPU processing power is now becoming evident, it has been coming for some time, with various activities prolonging the performance curve. It is not just Moore’s Law that is coming to an end with respect to processor performance but also Dennard Scaling and Amdahl’s Law. Processor performance over the last 40 years and the decline of these laws is displayed in the graph:
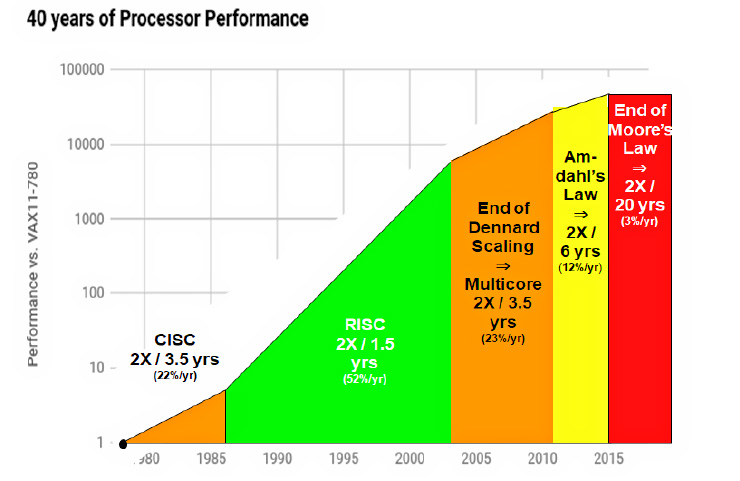
The advent of RISC computing in the 1980s was the basis for Gordon Moore’s initial prediction and faithfully showed a doubling in processor performance every 18 months. But, as the limits of clock frequency per chip began to appear, the use of Dennard scaling and multicore CPUs helped prolong the performance curve. But it is important to note that even at the start of the century, we were no longer on the Moore’s Law curve, and doubling of performance took 3.5 years during this time.
Amdahl’s Law refers to the limits of performance improvement that can be achieved with parallel processing. While parallelizing the execution of a process can provide an initial performance boost, there will always be a natural limit, as there are some execution tasks that cannot be parallelized. We have recently experienced that these limits come into effect when the benefits of using multiple CPU cores decrease, leading to an even longer time span between performance improvements.
The prediction, as can be seen in the graph, is that it will now take 20 years for CPU processing power to double in performance. Hence, Moore’s Law is dead.
Major readjustment of commonly held beliefs
Moore’s Law has been such a dependable and reliable phenomenon for so long that many of us have taken it for granted. It has been true since the 1980s, spanning the entire working life of many computer engineers. Most of us cannot envisage a world where this law is not true.
Of concern is that entire industries have been built on the premise of Moore’s Law and the continued expectation of constant processing performance improvement.
For example, the entire software industry assumes that processing power will increase in line with data growth and will be capable of servicing the processing needs of the software of the future. Therefore, efficiency in software architecture and design is less integral. Indeed, there is an ever-increasing use of software abstraction layers to make programming and scripting more user-friendly, but at the cost of processing power.
Virtualization, for example, is widely used but is a software abstraction of underlying physical resources that creates an additional processing cost. On one hand, virtualization makes more efficient use of hardware resources but, on the other hand, the reliance on server CPUs as generic processors for both virtualized software execution and processing of input/output data places a considerable burden on CPU processors.
To appreciate the consequences of this, look at the cloud industry and, more recently, the telecom industry. The cloud industry has been founded on the premise that standard Commercial-Off-The-Shelf (COTS) servers are powerful enough to process any type of computing workload. Using virtualization, containerization, and other abstractions, it is possible to share server resources amongst multiple tenant clients with “as-a-service” models.
Telecom carriers have been inspired by this model and the success of cloud companies to replicate this approach for their networks with initiatives such as SDN, NFV, and cloud-native computing.
However, the underlying business model assumption here is that as the number of clients and volume of work increases, it is enough to simply add more servers. But, as can be clearly seen in the earlier graph, server processing performance will only grow 3% per year over the next 20 years. This is far below the expectation that the amount of data to be processed will triple over the next five years.
Enter hardware acceleration
What you might reasonably ask at this point is why the problems with the slowdown of processor performance have not manifested themselves more readily. Cloud companies seem to be succeeding without any signs of performance issues. The answer is hardware acceleration.
Cloud companies were the first to recognize the death of Moore’s Law and were also the first to experience the performance issues related to it. But the pragmatism that led cloud companies to be successful also influenced their reaction to this situation. If server CPU performance power will not increase as expected, then they would need to add processing power. In other words, there is a need to accelerate the server hardware.
The authors of “Computer Architecture: A Quantitative Approach,” Turing Award prize winners John Hennessey and David Patterson, address the end of Moore’s Law. They point to the example of Domain Specific Architectures (DSA), which are purpose-built processors that accelerate a few application-specific tasks.
The idea is that instead of using general-purpose processors like CPUs to process a multitude of tasks, different kinds of processors are tailored to the needs of specific tasks. An example they use is the Tensor Processing Unit (TPU) chip built by Google for Deep Neural Network Inference tasks. The TPU chip was built specifically for this task, and since this is central to Google’s business, it makes perfect sense to offload to a specific processing chip.
All cloud companies have used acceleration technologies of one type or another to accelerate their workloads. Graphics Processing Units (GPUs) have been adapted to support a vast array of applications and are used by many cloud companies for hardware acceleration. For networking, Network Processing Units (NPUs) have been widely used. Both GPUs and NPUs provide a very large number of smaller processors where workloads can be broken down and parallelized to run on a series of these smaller processors.
The case for FPGA
Back in 2010, Microsoft Azure chose a different path: FPGAs.
Field Programmable Gate Arrays (FPGAs) have been around for more than 40 years. They have traditionally been used as an intermediary step in the design of Application Specific Integrated Circuit (ASIC) semiconductor chips. The advantage of FPGAs is that the same tools and languages are used as those used to design semiconductor chips, but it is possible to rewrite or reconfigure the FPGA with a new design, on the fly. The disadvantage is that FPGAs are bigger and more power-hungry than ASICs.
However, as the cost of producing ASICs began to increase, it became harder and harder to justify making the investment in ASIC production. At the same time, FPGAs became more efficient and cost-competitive. It therefore made sense to remain at the FPGA stage and release the product based on an FPGA design.
Today, FPGAs are widely used in a broad range of industries, especially in networking and cybersecurity equipment, where they perform specific hardware-accelerated tasks.
Microsoft Azure was inspired to explore the idea of using FPGA-based SmartNICs in standard severs to offload compute- and data-intensive tasks from the CPU to the FPGA. Today, these FPGA-based SmartNICs are used broadly throughout Microsoft Azure’s data centers, supporting services like Bing and Microsoft 365.
The emergence of FPGAs as a credible alternative for hardware acceleration led to Intel purchasing Altera in 2015, the second largest producer of FPGA chips and development software, for $16 billion.
Since then, several cloud companies have added FPGA technology to their service offerings, including AWS, Alibaba, Tencent and Baidu, to name a few.
Why FPGAs?
One of the attractions of FPGAs is that they provide a good compromise between versatility, power, efficiency and cost.
FPGAs can be used for virtually any processing task. It is possible to implement parallel processing on an FPGA, but it is also possible to implement other processing architectures. One of the attractions of FPGAs is that details such as data path widths and register lengths can be tailored specifically to the needs of the application. Indeed, when designing a solution on an FPGA, it is best to have a specific use case and application in mind in order to truly exploit the power of the FPGA.
When it comes to power, there is a vast array of choice for FPGAs even just considering the two largest vendors, Xilinx and Intel. For example, compare the smallest FPGAs that can be used on drones for image processing, to extremely large FPGAs that can be used for machine learning and artificial intelligence. FPGAs generally provide very good performance per watt. For example, FPGA-based SmartNICs can process up to 200 Gbps of data without exceeding the power requirements on server PCIe slots.
Since FPGAs are reconfigurable and can be tailored specifically to the application, it is possible to create highly efficient solutions that do just what is required, when required. One of the drawbacks of generic multi-processor solutions is that there is an overhead in cost due to their universal nature. A generic processor can do many things well at the same time but will always struggle to compete with a specific processor designed to accelerate a specific task.
There are a vast array of FPGA options on the market, and it is possible to find the right model at the right price point to fit your application needs. Like any chip technology, the cost of a chip reduces dramatically with volume, and this is also the case with FPGAs. They are widely used today as an alternative to ASIC chips, providing a volume base and competitive pricing that is only set to improve over the coming years.
Life after Moore’s Law
The death of Moore’s Law does not mean the death of computing. But it does mean that we must reconfigure our assumptions of what constitutes high-performance computing architectures, programming languages and solution design. Hennessey and Patterson even refer to this as the start of a new “golden age” in computer and software architecture innovation.
What is currently clear is that there are several technologies and solutions that can increase the performance of servers through hardware acceleration. FPGAs are emerging as an exciting, versatile and powerful option to explore.
About the author
Daniel Joseph Barry is VP Strategy and Market Development at Napatech and has over 25 years’ experience in the IT/Telecom industry. Dan Joe is responsible for identifying and developing new market opportunities for Napatech. Prior to joining Napatech in 2009, Dan Joe was Marketing Director at telecom chip vendor TPACK (now Intel). This follows roles as Director of Sales and Business Development at optical component vendor NKT Integration (now Accelink), development and product management roles at Ericsson and research roles at Jutland Telecom (now TDC). He has an MBA and a BSc degree in Electronic Engineering from Trinity College Dublin.
So the time has come to optimise the software stack after years of “We do it later”, now we can spend our time on optimising our stack!!!!