More and more user interfaces now consist of a conversation. New development hardware makes it easier to ‘talk’ to devices without physically touching anything.
Vikram Shrivastava, Knowles Corp.
More and more IoT devices these days will understand what you say when you talk to them. Voice is still in the early phases of adoption, however, and is just beginning to expand beyond mobile devices and speakers. Eventually voice will become the standard way users interact with their IoT devices. But to date, voice interactions are generally limited by inconsistent sound quality in the presence of noise and other distractors. This can degrade the end-user experience and slow the adoption of voice technology.
The traditional approach to voice applications has been to record the voice commands and send them to the cloud for processing. But to take advantage of maturing voice integration, processing technologies are moving to the edge, away from the cloud. The approach lowers latency and reduces costs, both in dollars and bandwidth. But the current challenges with employing voice still include power consumption, latency, integration, and privacy. There are design approaches and technical guidance that can facilitate audio edge processing when designing IoT voice applications.
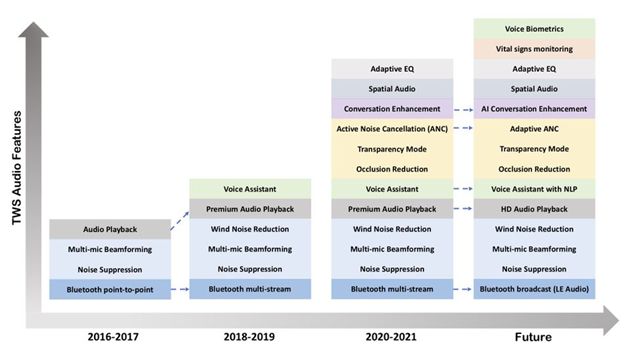
As more applications employ voice-calling, control, and interactions, the field becomes more fragmented. The fragmentation diminishes the chance of guaranteeing a successful voice implementation by following a few basic rules-of-thumb. Voice control is integrated differently into each application—be it Bluetooth speakers, home appliances, headphones, wearables, or elevators. It might be simple to add a voice wake-trigger. Designing voice into an enterprise-grade Bluetooth speaker and headset will probably be complex—even more so if the speaker includes true wireless stereo (TWS) integration.
Additionally, different hardware platforms by require different voice integration approaches. For instance, voice integration on most smart TVs entails work in a Linux ecosystem. But adding voice on a home appliance will require working in a microcontroller (MCU) ecosystem. There is a common, recommended method for all of these integrations, but there are always variations that complicate the task.
The voice user interface
It is expected that always-on Voice User Interface (VUI) will become commonplace in numerous consumer products. But inconsistent sound quality in the presence of noise and other distractors can make voice interactions annoying. Whether or not a device can intelligently manage sound can ultimately make or break a user’s ability to communicate effectively. Integration of audio edge processors into devices is one way of adding reliable always-on VUI capabilities.
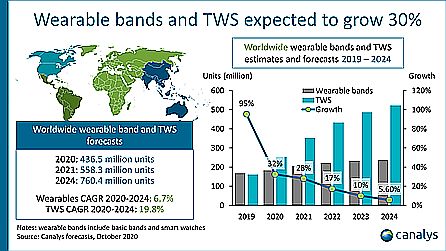
Dedicated audio edge processors containing machine-learning-optimized cores are the key to devising high-quality audio communication devices. These processors can deliver enough compute power to process audio using traditional and ML algorithms while dissipating much less energy than a generic processor. Because the processing happens directly on the device, the process is significantly faster than sending that information to the cloud and back.
Use of audio processors can also help add capabilities like voice-wake. While the cloud may offer some great benefits, edge processing allows users to use their device without a high-bandwidth internet connection. For example, edge audio processors enable low-latency audio processing with contextual data while also keeping the contextual data local and secure.

Nevertheless, there are some common challenges with implementing VUIs for IoT always-on and listening devices:
Power consumption–A VUI device must be always-on/always-listening to receive commands. In a voice-command system, at least one microphone must always be active, and the processor tasked with recognizing the wake word must also be active. However, audio edge processors designed with proprietary architectures, hardware accelerators, and special instruction sets can run audio and ML algorithms optimized to reduce power consumption.
Latency–There is no tolerance for latency with voice-activated devices. A perceived delay exceeding just 200 msec will bring people to talk over each other on voice calls or repeat their commands to the voice assistant. Engineers and product designers must optimize the audio chain to limit latency. Low-latency processing in edge processors is thus critical for ensuring high-quality voice communication.
Integration–There are many options for hardware and software for different VUI implementations. Optimal hardware architectures for implementing a VUI system depend on the device usage, application, and ecosystem. Each VUI device will include either a single microphone or a microphone array, connected to an audio processor. And there are numerous operating systems and drivers to choose from. Ideally the audio processor will come with firmware and a set of drivers configured to connect with the host processor. The operating system, such as Android or Linux, usually runs on the host.
Driver software components that run in the kernel space interact with the firmware over the control interface, and audio data from the audio edge processor can be read in the user space via a standard Advanced Linux Sound Architecture (ALSA) interface. The process of connection the audio processor driver provided in the software release package into the kernel image can be complicated. It involves copying the driver source code into the kernel source tree, updating some kernel configuration files, and adding device tree entries according to the relevant hardware configuration.
An alternative would be to use pre-integrated standard reference designs with exact or similar configurations. Ideally, the audio edge processor would provide streamlined software stacks for integration and come with pre-integrated and verified algorithms to further simplify the process.
Algorithm integration
There are typically multiple algorithms employed for any given use case. Even for a relatively simple Voice Wake, multi-mic beamformers, an edge voice wake engine, and cloud-based verification algorithms are all necessary. So at least three algorithms must work together synchronously to optimize performance. Any device integrating Alexa or Google Home keywords must employ multiple algorithms, often coming from different vendors, that must be optimized to work together in one device. To simplify things, it might be possible to choose an audio edge processor that comes pre-integrated with verified algorithms and is developed and tested independent of the host system.
Form Factor Integration—Modern devices can take on numerous form factors, each having its own configuration of multiple microphones. The distance and placement of microphones and speakers both play a big role in performance. Performance tuning and optimization depend on the final form factor and target use. Aspects of mechanical engineering–such as microphone sealing, acoustic treatments on the device, vibration dampening, and more—may also impact performance.
Privacy–Many audio processors detect the wake word and then immediately beam the information to the cloud for interpretation. But once the audio data is in the cloud, the user loses control over the information it contains and is at risk of a privacy breach. To avoid the problem, an edge AI processor can interpret commands and respond locally, “at the edge.” The Voice user interface (VUI) implementation not only becomes private but also speeds up, making user interactions much more natural.
Designing VUIs

The complexity of design requirements for VUI implementations can make it challenging to quickly develop such products. OEMs and system integrators can drastically reduce risk by working with a standard development kit. This approach lets designers develop their product on a platform that eliminates the challenges that arise in VUI projects. Designers should look for development kits having pre-integrated and verified algorithms, pre-configured microphones, and drivers that are compatible to the host processor and operating systems.
Audio edge processors incorporating open architectures and development environments accelerate innovation by giving developers the tools and support to create new devices and applications. Future audio devices will be a collaborative effort.



Leave a Reply