Machine learning (ML) is a subset of artificial intelligence (AI). It’s used to enable machines to independently improve their performance using data and experience to modify future actions. ML applications range from autonomous vehicles to business processes. Various approaches to ML use different learning styles, require different levels of data input, and are optimized for specific types of tasks.
Regardless of the style of learning, once the system has been trained, it’s expected to operate autonomously. The four most common approaches to ML are supervised learning, unsupervised learning, semi-supervised learning, and reinforced learning (Figure 1).
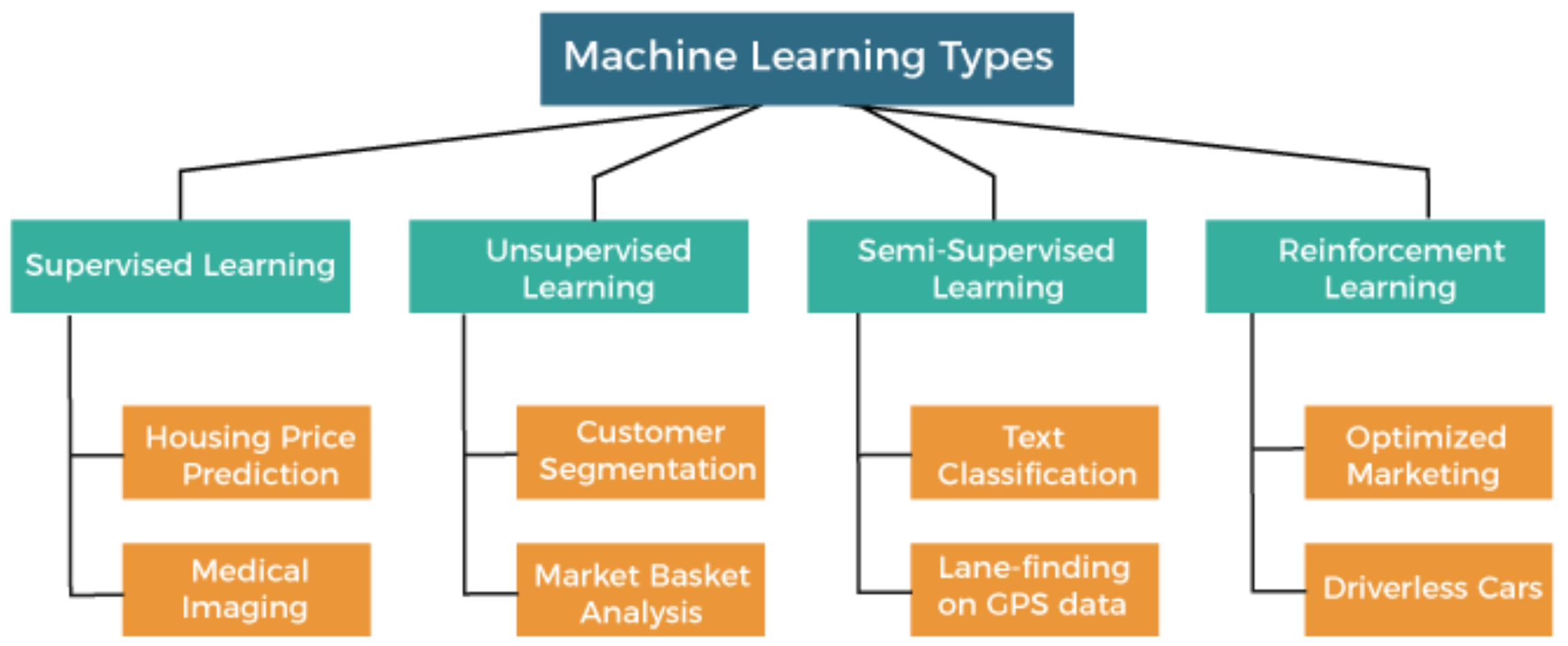
Supervised learning
In supervised learning, the machine is taught using labeled datasets. The operator provides the machine learning algorithm with an example dataset that includes expected inputs and outputs. The algorithm identifies a method to determine how to use the supplied inputs to arrive at the expected outputs, and the operator corrects any errors. Supervised learning is an iterative process where the predictions by the algorithm are expected to be closer and closer to the expected result. The learning process continues until the required level of accuracy has been achieved.
Supervised learning relies on accurately labeled datasets that include a sufficient level of detail. This type of learning has two primary uses, classification and predicting continuous outcomes:
- Classification models are trained to identify data types. Some applications include identifying spam emails, facial identification, and image recognition.
- Prediction models are trained to identify patterns within a dataset. Prediction models are used for forecasting retail sales, stock trading applications, healthcare, and advertising planning to predict the value of specific ad spaces or programs.
Semi-supervised learning
Semi-supervised learning uses a combination of labeled and unlabeled datasets. It begins with supervised learning using a labeled dataset. Next, the clustering process is used in unsupervised learning to group the unlabeled dataset. Semi-supervised learning is especially useful when large datasets are involved, and it would be too costly to manually analyze the categorize all the data. Examples can include large amounts of text data from large groups of images.
There are several common uses for semi-supervised learning:
- Grouping text documents like books, legal briefs, technical reports, and so on.
- Categorizing large libraries of image or audio files when an adequate sample of labeled data is available.
Unsupervised learning
In this case, the ML algorithm independently analyzes large quantities of data to identify patterns. The algorithm is designed to organize the data in some way that describes its structure. Common analysis techniques include:
Clustering that groups sets of similar data (based on specified criteria). It’s used to organize data into multiple smaller datasets and analyze each of the smaller datasets to find patterns.
Dimension reduction literally reduces the number of variables being considered to find the exact information required. It can be used to refine clusters. And it delivers a simplified model that can be more efficient to implement.
Visualization can be used to create charts and graphs. Data visualization can also incorporate clustering to develop different smaller datasets that are then used to plot data across two or more dimensions. Data visualization can be especially useful to assist human analysis in digging deeper into complex datasets.
Reinforcement learning
Reinforcement learning is inherently different from the other types of ML reviewed above. Reinforcement learning does not require a training dataset; it learns by interacting with the environment. The process involves a feedback loop where successful outcomes are rewarded or reinforced, and failures get a negative signal. The system learns by trial and error to arrive at the best possible outcome.
A common reinforcement learning technique involves the Markov Decision Process (MDP). MDP can be used to model decision-making and learning in situations where outcomes are partly controlled and partly random.
The development of autonomous cars is an example of reinforcement learning. The car learns the best course of action from its environment, but the outcome is only partly under the control of the system. There are numerous independent external factors that also need to be considered. That type of environment is well suited to using MDP for decision-making.
Beyond the basics
The four types of machine learning described above are not an exhaustive list. They only cover some of the basics. There are many other approaches (Figure 2). For example, a deductive learning model is based on a series of logical principles and steps, while inductive ML is based on using examples or observations for training. Multi-task learning is a variation of inductive learning in which multiple learning tasks are solved simultaneously while also taking advantage of commonalities and differences between the tasks. Multiple instance learning is a subset of supervised learning where subsets of the primary dataset are grouped under a single label.

Summary
ML is an important subset of artificial intelligence. It’s used across a wide range of applications, and multiple techniques have been developed for training ML algorithms depending on the quantity and quality of the available training dataset.
References
A guide to the types of machine learning algorithms and their applications, SAS
Four Types of Machine Learning Algorithms Explained, Seldon
Types of Machine Learning, JavaPoint
Types Of Machine Learning, Nixus


Leave a Reply