Most edge AI demonstrations operate flawlessly in controlled environments with stable networks, predictable traffic, and carefully managed credentials. In contrast, many production deployments fail under real-world conditions.
This technical article outlines the best practices required for reliable edge AI deployment. It covers bandwidth planning for peak conditions and buffering strategies that maintain stability during degraded connectivity. The article also reviews automated certificate lifecycle management and presents a cost–benefit framework for evaluating when cloud connectivity adds value and when it introduces unnecessary cost or risk.
Plan bandwidth with explicit per-site budgets
The most common edge AI deployment failures assume cloud transmission is free from bandwidth constraints or cost impact. To prevent cost and latency penalties, production systems must define per-site bandwidth and cost budgets that account for peak conditions rather than average utilization.
As shown in Figure 1, AI workloads such as industrial vision, autonomous perception, and retail analytics generate bursty traffic from video frames, embeddings, and event batches. Links that appear adequate in a dashboard demonstration often saturate under field conditions, introducing jitter, packet loss, and cascading timeouts.

Deployment-ready designs should partition data flows into three categories:
- Local data: Keep raw sensor streams within the local network.
- Edge processing: Produce compact outputs such as anomaly scores, detection bounding boxes, or feature embeddings that require significantly less bandwidth.
- Selective uploads: Transmit full-resolution samples only when triggered by anomalies, uncertainty thresholds, or scheduled audits.
This partitioning guides peak-load planning by defining what data stays local and what data moves upstream.
Model peak load accurately
Peak bandwidth estimates should model worst-case simultaneous activity across all nodes on a shared segment. A single 1080p video stream at 30 frames per second generates about 8 to 12 megabits per second before compression. Ten concurrent inference streams without local processing can saturate enterprise-grade connections.
As shown in Figure 2, embedding vectors from a ResNet-50 model occupy about 8 kilobytes per inference. Transmitting these compact representations instead of raw frames reduces bandwidth demands by factors of 100 or more while retaining key information for centralized analytics.

Cost planning must evaluate bandwidth charges, cloud ingress fees, storage costs, and inference API expenses. Streaming full video often exceeds the value of the insights it supports, particularly in high-volume or low-margin deployments. Enforced bandwidth budgets, implemented through configuration and code, prevent individual nodes from consuming shared resources and reduce the risk of fleet-wide instability.
Although bandwidth budgets constrain transmission rates, deployments must also maintain operation when available bandwidth fluctuates.
Implement buffering and backpressure to prevent cascading failures
Edge AI demonstration code often assumes the network provides unlimited buffering capacity, absorbing any volume of data without delay or loss. Production systems require explicit buffering strategies and backpressure mechanisms for each link and workload, with rules for what to drop, downsample, or delay when network conditions degrade.
Deployment-ready designs should implement three controls:
- Size-bounded queues: Allocate local queues for credible outage durations to prevent memory exhaustion and maintain application stability. For example, a factory vision system may buffer 60 seconds of anomaly detections to ride through short connectivity losses without losing critical alerts.
- Activate fallback modes: Maintain real-time inference, local alerting, and closed-loop control during extended disconnections. Safety functions don’t rely on a remote round-trip. High-priority events remain in local storage until connectivity returns, then upload through rate-limited background processes.
- Apply backpressure upstream: Reject new data at the source, reduce sampling rates, or shift to lower-fidelity modes when downstream components can’t keep pace. These controls prevent saturated links from causing memory pressure, application failures, or data loss across multiple subsystems.
While buffering strategies maintain operational continuity during network failures, deployments must also secure device identity and authentication at scale.
Scale certificate management through automation and hierarchy
Edge AI demonstrations typically use shared keys or manual provisioning to simplify setup and avoid the overhead of managing device identities at scale. In production, each device must hold a unique cryptographic identity with automated issuance, rotation, and revocation across the full lifecycle.
As shown in Figure 3, production deployments span heterogeneous field devices, message brokers, and cloud services that securely authenticate across edge-cloud boundaries.
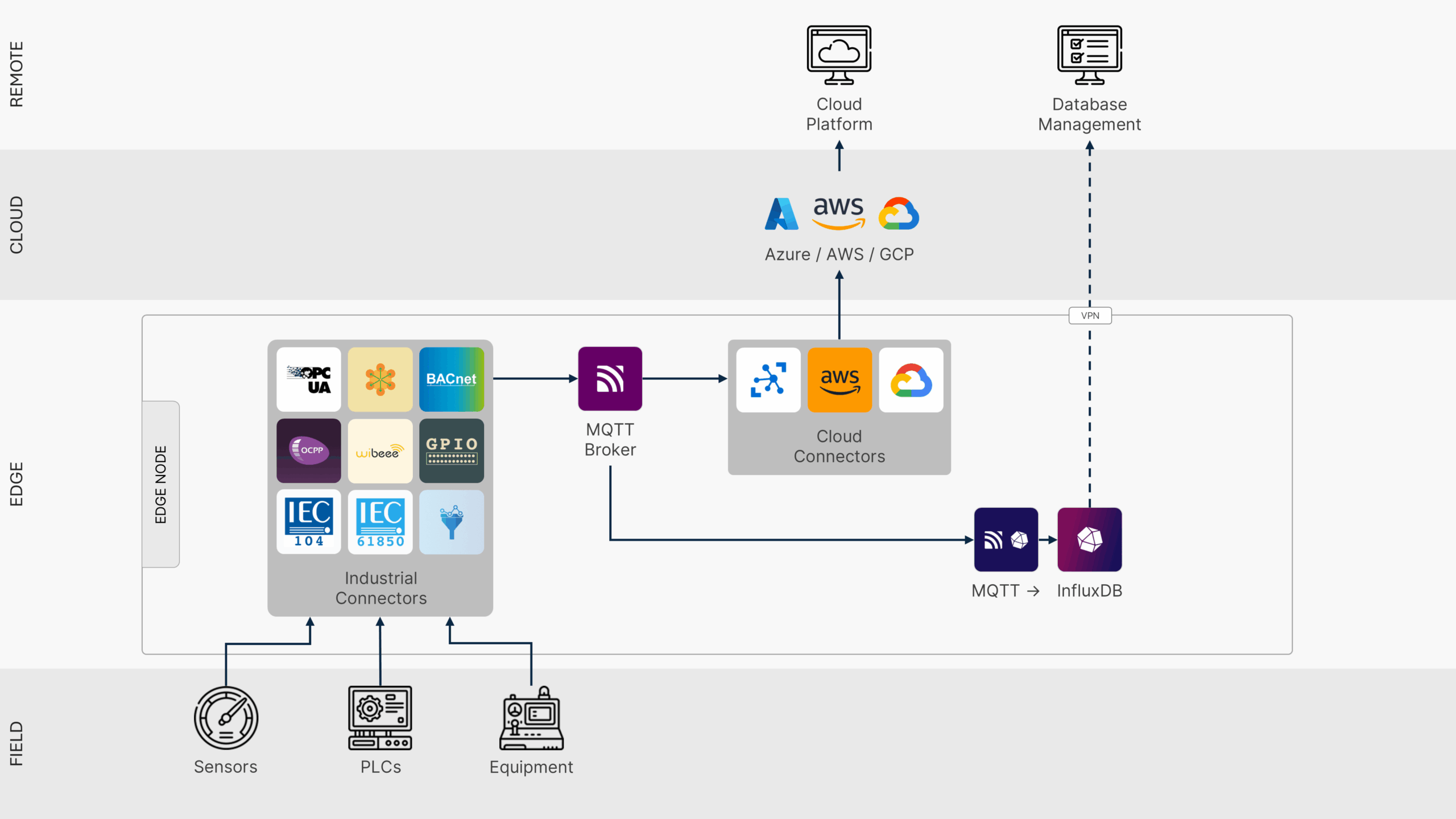
To support this requirement, a public key infrastructure or cloud IoT identity service should provide zero-touch provisioning, with devices obtaining certificates automatically during their initial connection. Segmented certificate hierarchies separate test and production roots, isolate customer tenants, and limit the scope of a compromise.
Automated rotation cycles refresh device certificates at predictable intervals, often every 90 days, while root certificates persist for one to three years. Rotation occurs during normal operation without service interruption, and systems must track expiration dates and initiate renewal well before certificates lapse.
Edge AI deployments also require revocation mechanisms that invalidate compromised credentials across the fleet. Certificate revocation lists or online status services allow devices to verify peer certificates before establishing connections. These controls prevent compromised devices from communicating with backend systems or other nodes, even if private keys are exposed.
With identity and authentication secured, deployments must also determine whether cloud connectivity supports the application or instead introduces unnecessary risk.
Identify when cloud connectivity becomes a disadvantage
Edge AI cloud connectivity is counterproductive when excessive data transfers or round-trip times increase cost, latency, or operational risk more than they improve outcomes. This occurs when systems stream high-rate sensor data for time-critical decisions, pay more in egress and inference fees than the resulting insights justify, or rely on cloud services for functions that must continue during network outages.
As shown in Figure 4, systems that offload time-critical tasks to remote cloud servers face higher delays and increased failure rates compared to local edge execution. Latency-sensitive workloads should leverage local inference because their control loops operate within tight time budgets.

Manufacturing defect detection typically must respond within 50 milliseconds. Autonomous vehicle perception and control loops execute in 10 to 20 milliseconds, and robotics safety systems act within single-digit milliseconds. Cloud round-trip times often exceed 50 to 100 milliseconds before processing delays, so they can’t support workloads requiring deterministic response times.
Cost evaluations should compare cloud processing expenses with local compute investment. Cloud inference APIs charge per request and add data transfer fees, while dedicated edge hardware can reduce per-inference costs within months for high-volume deployments. Local processing also avoids variable cloud costs that increase during usage spikes.
Hybrid architectures can address these latency and cost constraints by keeping real-time inference and closed-loop control local. Cloud infrastructure then supports fleet-level management, model distribution, and analytics that tolerate longer latencies. This structure maintains local autonomy while using centralized resources where they add value.
Summary
Production edge AI deployments require strategic planning for bandwidth budgets, buffering strategies, certificate lifecycle management, and hybrid architectures. Bandwidth planning must enforce per-site limits based on peak conditions, while buffering strategies should maintain operation during degraded connectivity through bounded queues and fallback modes. Certificate management must automate issuance and renewal under a structured public key infrastructure, and hybrid architectures should reserve cloud connectivity for tasks that benefit from centralization while keeping time-critical functions local.
References
Why Edge AI Struggles Towards Production: The Deployment Problem, Edge AI Vision Alliance
Why Edge AI Fails — And Why the Missing Infrastructure Layer Matters More Than the Models, Felix Galindo
Beyond Deployment: How to Keep Edge AI Models Learning in the Field, Seco
How to Implement Device Management for Large-Scale IoT Deployments, Inspiro
Edge AI vs. Cloud AI: Understanding the Benefits and Trade-Offs of Inferencing Locations, EdgeIR
AI is on the Edge and Network Jitter is Pushing It Over, BaduNetworks
Edge AI vs Cloud AI vs Distributed AI: What You Need To Know, IO River
Best Practices for Large-Scale IoT Device Deployments, Microsoft
Edge AI – Implementation of Artificial Intelligence on Edge Devices, Ardura
Related EE World content
Benchmarking AI From the Edge to the Cloud
What Specifications Are Needed for Card Edge Connectors in AI/ML Systems?
Shaping the Future with Embedded AI
The Intelligent Edge: Powering Next-Gen Edge AI Applications
Smart Buildings and the IoT: Zoning Systems


Leave a Reply