Edge AI is no longer experimental. From wearables and medical sensors to smart home devices, industrial monitors, and infrastructure nodes, products are increasingly expected to sense, analyze, and make decisions locally while operating for months or even years on small batteries. This requirement has turned ultra-low-power system design into one of the most complex challenges in modern embedded engineering.
Despite advances in semiconductor processes that reduce dynamic power and leakage, growing software complexity and the addition of more sensors mean the battery often becomes the limiting factor. System designers seek SoCs that promise longer battery life, while chip vendors promote efficiency metrics such as DMIPS per milliwatt or microwatts per MHz. Yet higher processor efficiency numbers alone do not automatically translate into longer operational lifetime.
Many developers encounter power specifications expressed in µW/MHz, which indicate how much power a processor consumes at a given clock frequency. While useful for comparing processor cores under active workloads, this metric can be misleading in real systems. Edge devices rarely operate continuously at peak performance. Instead, they spend most of their time sleeping, waking briefly to process data before returning to low-power states. In practice, battery life depends less on peak efficiency and more on duty cycle and power-state behavior.
Battery life ultimately reflects how long a system remains in each power state and how much energy each state consumes. Two processors with identical efficiency ratings can produce dramatically different battery lifetimes if one wakes more frequently, runs longer to complete tasks, or expends additional energy moving data between memory and compute resources. In edge AI systems, overall energy efficiency depends on how computation, memory, and peripherals interact across the entire architecture.
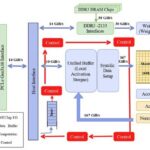
For this reason, modern edge designs increasingly rely on heterogeneous computing architectures that distribute workloads across multiple processing engines rather than relying on a single general-purpose core.
Choosing between MCU, DSP, and AI accelerators
One of the most important architectural decisions in edge AI systems is determining how different compute engines collaborate. Microcontroller cores, digital signal processors (DSPs), and neural accelerators each serve distinct roles.
General-purpose MCUs provide flexibility and are well-suited for control logic, sensor management, and system coordination. DSP engines are optimized for signal-processing tasks such as filtering, spectral analysis, and FFT operations commonly used in audio, vibration, and environmental sensing. Dedicated neural accelerators or NPUs provide the highest efficiency for machine-learning inference workloads dominated by multiply-accumulate operations.
Selecting the right balance between these resources requires careful workload characterization. Developers must determine which tasks are continuously active, which occur intermittently, and which consume the most system energy. Machine-learning models also require optimization before deployment, using techniques such as quantization, pruning, and operator fusion, to reduce memory footprint and computational demand.
When properly partitioned, heterogeneous resources can significantly reduce energy consumption. Signal-processing stages can execute on DSP hardware, inference workloads can run on neural accelerators, and supervisory control can remain on low-power cores. This division allows the system to remain responsive while minimizing the time spent in higher-power operating states.
Architecture matters more than core efficiency
As edge AI workloads grow more complex, system architecture increasingly determines overall energy efficiency. Designs that separate processing responsibilities across multiple compute domains can minimize active power consumption while preserving performance when needed.
This approach typically includes a low-power subsystem responsible for continuous sensing and event monitoring, combined with higher-performance compute resources that activate only when heavier processing is required. Supporting components such as power-state control logic, clock management, and interrupt systems enable software to transition efficiently between operating modes.
Equally important is reducing the energy cost of moving data. In many AI workloads, transferring data between memory and compute engines can consume more power than the computations themselves. Architectures that position accelerators near memory resources or incorporate specialized processing blocks can significantly reduce this overhead.
By treating power management as a core architectural element rather than an afterthought, developers can extend battery life while still supporting meaningful edge intelligence.
Edge AI in practice
Consider a typical edge AI application such as keyword detection, anomaly monitoring, or vibration analysis. A low-power sensing subsystem continuously monitors incoming sensor signals while the primary processor remains in deep sleep. When a potential event is detected, a higher-performance compute resource wakes to perform signal processing and data analysis.
Preprocessing stages often involve DSP operations such as filtering or FFT transforms to convert raw signals into useful features. The resulting data can then be passed to a machine-learning inference engine for classification. Once processing is complete, the system returns quickly to a low-power state.
This workflow illustrates why edge AI efficiency depends on system-level orchestration rather than raw processor speed. Minimizing active time and mapping workloads to the most efficient compute resources allows designers to maintain responsiveness while preserving battery life.
When custom RISC-V extensions make sense
Incidentally, the integration of NPU accelerators with RISC-V cores has attracted significant attention and made impressive progress, as edge AI has made NPUs almost a must-have in SoCs. While attaching the NPU to the high-speed bus as a standalone DMA master is a proven approach, small SoCs with a small accelerator may benefit from a tightly coupled scheme that further reduces latency and data movement.
In many embedded AI workloads, vector or matrix operations dominate execution time. Targeted hardware acceleration for these operations can substantially improve both performance and energy efficiency. However, each target accelerator has a different combination of features, performance, and size, resulting in a vast array of variants. The booming popularity of compute-in-memory (CIM) specialty modules, both analog and digital-based, adds to the push for a systematic integration solution. Thanks to leading IP vendors and research institutions, we now have multiple established custom extension interfaces for integrating NPUs of our choice. It is by no means a small undertaking, but designers can evaluate whether this route provides measurable system-level benefits and justifies the upfront investment.
Meanwhile, we are not ruling out the possibility that certain light workloads may be handled by the RVV-equipped CPU alone. Obviously, the vector extension itself adds little overhead if the chip already includes an NPU. As vector extensions and domain-specific accelerators become more widely available, we will likely see more intricate arrangements for the real-time, mixed-use of RVV and NPU to achieve the best energy efficiency for each edge application.
From architecture to real-world deployment
Edge AI is increasingly defined not by raw compute capability but by how efficiently computation is orchestrated across the entire system architecture. Achieving meaningful battery life requires understanding real workloads, carefully managing power states, and mapping each stage of processing to the most efficient compute resource.
Platforms such as the UP201 and UP301 from Upbeat Technology illustrate how these architectural principles are being implemented in modern edge-AI systems. Built around a heterogeneous RISC-V architecture with multiple processing domains, DSP capabilities, and neural-network acceleration, the devices are designed to support battery-powered intelligent applications, including smart sensors, voice interfaces, predictive maintenance nodes, and other always-on monitoring systems.
As embedded intelligence continues to move closer to the edge, architectures that intelligently combine processing, scalable acceleration, and flexible instruction sets will play a critical role in making practical, battery-powered AI devices possible at scale.


Leave a Reply