Domain specific accelerators (DSAs) are specialized hardware computing engines optimized for specific tasks. DSAs have been developed for graphics, simulation, image processing, deep learning, bioinformatics, and other tasks. Compared to general purpose processors, accelerators offer orders of magnitude improvements in performance/cost and/or performance/watt. The previous FAQ in this series, “What’s the future for RISC-V in 5G?,” included a discussion of an application-specific DSA to implement neural networks for 5G radio resource management. This article will review more general purpose DSAs, including those designed for digital signal processing applications, cryptography, and deep learning.
Initially, DSAs were developed to lower the execution time for, particularly computationally intensive tasks. More recently, DSAs are being adopted to lower the energy consumption needed to perform a task. Even if the DSA’s peak power consumption is greater than the peak power consumed by a general purpose processor, the task execution time is reduced by such a large amount that the total energy required to complete a task is lower. Like memory, RISC-V DSAs can be implemented on the same silicon as the processor core using system on chip (SoC) designs or implemented as system in package (SiP) designs.

The four primary techniques used in DSAs to enhance performance and energy efficiency are:
- Data specialization enables the use of specialized operations in one cycle that may take tens of cycles on a conventional computer. And specialized logic can be used to perform an inner-loop function gains in both performance and efficiency.
- High degrees of parallelism are often used at multiple levels, providing gains in performance.
- Local and optimized memory stored in many small and local data structures can provide high bandwidth with low energy consumption and low cost. Common data structures can be compressed for further performance improvements.
- The use of specialized hardware eliminates or reduces the overhead of program interpretation.
DSP optimized DSA
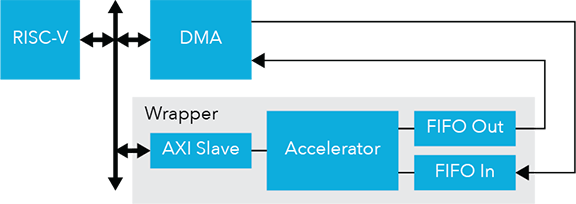
These techniques are on display in a DSA optimized for digital signal processing (DSP) applications in energy-efficient Internet of Things (IoT) devices. This configurable DSA is designed to support applications such as mono-dimensional and bi-dimensional filtering, pattern matching, and image processing. This configurable DSA provides faster execution and lower energy consumption than conventional software execution of the same application on a standard RISC-V core.
This flexible DSA can be reconfigured by a local control unit, based on instructions from the main RISC-V core to be optimized for specific DSP-oriented tasks. And the dynamic range of the DSA’s data path can be reduced depending on the application’s needs to increase energy savings. The disabling of the logic gates in the least significant bits of the processing elements, as appropriate, is used to adjust the dynamic range.
Post-quantum cryptography DSA
The goal of post-quantum cryptography (PQC, also called quantum-resistant cryptography) is to develop cryptographic systems that are secure against both quantum and classical computers and can interoperate with existing communications protocols and networks. The development of practical PQC for electronic devices is challenging since PQC requires new mathematical elements and operations that cannot be easily or efficiently implemented with standard processors. The use of hardware-based DSAs can be especially important for low-cost, resource-constrained devices such as IoT nodes. RISC-V can improve the flexibility of PQC implementations and, since the standardization of PQC is not finalized, flexibility supports changes that may be needed as the standard is developed. Hardware/software co-design is often needed to develop complex and effective PQC solutions.
Researchers have recently developed an enhancement to the RISC-V architecture that integrated tightly-coupled DSAs and an extension to the RISC-V ISA with 29 new instructions for PQC. Called RISQ-V, the new core and DSA combination efficiently reuses processor resources and reduces the number of memory accesses. That results in increased performance while minimizing the increase in overhead.
RISQ-V has been implemented as an ASIC and on an FPGA, and its performance has been evaluated for the NewHope, Kyber, and Saber implementations of PQC. Compared to the pure software implementation on RISC-V, the co-design implementation of RISQ-V shows a speedup factor of up to 11.4 for NewHope, 9.6 for Kyber, and 2.7 for Saber. For the ASIC implementation, the energy consumption was reduced by factors of up to 9.5 for NewHope, 7.7 for Kyber, and 2.1 for Saber.
Creating DSAs with RISC-V
Custom DSA functions can be created on a RISC-V-based open infrastructure offered by Efinix. This accelerator socket framework has specific inputs and outputs to the RISC-V core, DMA controller, DSA function, and other processing blocks. This open framework includes pre-defined chip-level inputs, outputs and system interconnects to support DSA development in a scalable environment.
Hardware acceleration is important when implementing AI and vision at the edge in a range of applications such as automotive, industrial vision, retail, and robotics. The Efinix Edge Vision SoC framework, which uses a soft RISC-V SoC, supports domain-specific embedded software functions, DSA modules, memory, and I/O related interfaces, peripherals, and controllers for use in edge vision, AI in the IoT, and other applications.
European processor initiative
The development of DSAs is an important part of the European Processor Initiative (EPI) to develop and demonstrate fully European processor IPs based on the RISC-V ISA, providing power efficient and high throughput accelerator tiles within the general purpose processor (GPP) RISC-V chip. For example, the VaRiable Precision (VRP) unit enables efficient computation in scientific domains, such as physics and chemistry, with extensive iterative linear algebra kernels. Augmenting accuracy inside the kernel reduces rounding errors and therefore improves computation stability. Alternative solutions for this problem, such as double-precision in intermediate calculations, can have a very high impact on memory and computation time.
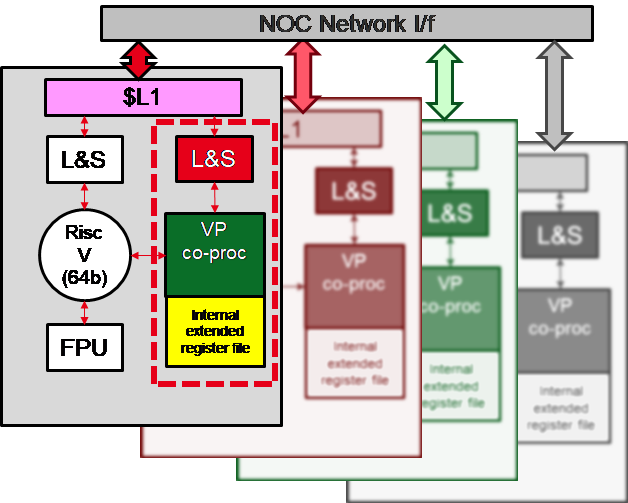
The VRP uses hardwired arithmetic basic operations in variable precision for scalars. The VRB includes an extension to the standard RISC-V ISA and features a dedicated register file for storing up to 32 scalars with up to 256 bits of mantissa precision. Its architecture is pipelined for performance, and it has internal parallelism of 64-bits.
Stencil/tensor accelerator
The EPI initially focused on developing “specialized blocks for stencil and deep learning (DL) acceleration.” The vector and stencil capabilities were expected to address workloads in high-performance computing centers. In contrast, the DL block was expected to target learning acceleration to address the need for optimized performance and energy efficiency for specialized calculations used in applications such as engineering and physics. However, researchers were able to merge the functionality of both units into a very efficient computation engine that has been named STX (stencil/tensor accelerator).
STX is designed to achieve at least 5-times better energy efficiency compared with general purpose vector processors. However, the effective efficiency of the EPI RISC-V cores plus the STX is significantly higher. For applications that require only inference using quantized networks, this efficiency will be another 10x higher.
Application-specific instruction set processors
An alternative to using a hardware DSA is the creation of an application-specific instruction-set processor (ASIP), which has a specialized architecture optimized to efficiently achieve the required performance, for example, for audio processing. Fixed function DSAs deliver the highest efficiency, while ASIPs deliver greater computational efficiencies than general purpose processors and more flexibility than fixed-function DSAs. Both approaches are being applied in the RISC-V environment.

An ASIP is an intermediate solution. Standard processor cores are designed to handle a range of applications with acceptable performance. When standard cores are used to perform computationally intensive applications such as audio processing, it can be necessary to use a higher clock frequency or a higher-performance core. In either case, that can result in a more costly device and higher power consumption. Designers can optimize overall cost/performance and efficiency tradeoffs by employing a mix of standard cores, ASIPs, and DSAs that are best suited to the specific application requirements.
Summary
DSAs are available for various applications, including graphics, simulation, image processing, deep learning, bioinformatics, and other tasks. Compared to general purpose processors, DSAs offer orders of magnitude improvements in performance/cost and/or performance/watt. This article has reviewed several aspects of DSA technology, including digital signal processing, post-quantum cryptography, and stencil/tensor acceleration.
References
Accelerator Stream, European Processor Initiative
Digital Signal Processing Accelerator for RISC-V, Technical University of Denmark
Quantum Accelerators, Efinix
RISQ-V: Tightly Coupled RISC-V Accelerators for Post-Quantum Cryptography,
What is an ASIP?, codasip

Leave a Reply