 NVIDIA opened the door for enterprises worldwide to develop and deploy large language models (LLM) by enabling them to build their own domain-specific chatbots, personal assistants, and other AI applications that understand language with unprecedented levels of subtlety and nuance.
NVIDIA opened the door for enterprises worldwide to develop and deploy large language models (LLM) by enabling them to build their own domain-specific chatbots, personal assistants, and other AI applications that understand language with unprecedented levels of subtlety and nuance.
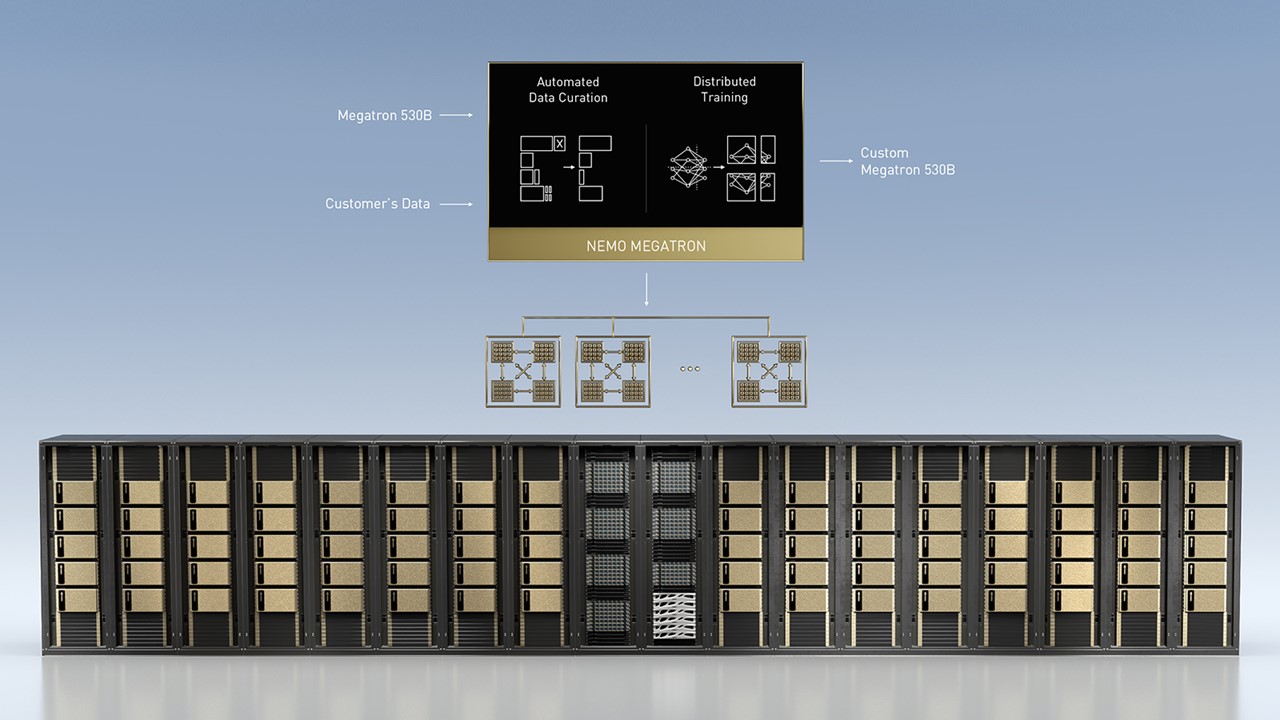
The company unveiled the NVIDIA NeMo Megatron framework for training language models with trillions of parameters, the Megatron 530B customizable LLM that can be trained for new domains and languages, and NVIDIA Triton Inference Server with multi-GPU, multinode distributed inference functionality.
Combined with NVIDIA DGX systems, these tools provide a production-ready, enterprise-grade solution to simplify the development and deployment of large language models.
NVIDIA NeMo Megatron builds on advancements from Megatron, an open-source project led by NVIDIA researchers studying efficient training of large transformer language models at scale. Megatron 530B is the world’s largest customizable language model.
The NeMo Megatron framework enables enterprises to overcome the challenges of training sophisticated natural language processing models. It is optimized to scale out across the large-scale accelerated computing infrastructure of NVIDIA DGX SuperPOD.
NeMo Megatron automates the complexity of LLM training with data processing libraries that ingest, curate, organize and clean data. Using advanced technologies for data, tensor, and pipeline parallelization enable the training of large language models to be distributed efficiently across thousands of GPUs. Enterprises can use the NeMo Megatron framework to train LLMs for their specific domains and languages.\
New multi-GPU, multinode features in the latest NVIDIA Triton Inference Server — announced separately — enable LLM inference workloads to scale across multiple GPUs and nodes with real-time performance. The models require more memory than is available in a single GPU or even a large server with multiple GPUs, and inference must run quickly to be useful in applications.
With Triton Inference Server, Megatron 530B can run on two NVIDIA DGX systems to shorten the processing time from over a minute on a CPU server to half a second, making it possible to deploy LLMs for real-time applications.
Among early adopters building large language models with NVIDIA DGX SuperPOD are SiDi, JD Explore Academy, and VinBrain.
Sidi has adapted the Samsung virtual assistant for use by the nation’s 200 million Brazilian Portuguese speakers.
JD Explore Academy, the research and development division of JD.com, a leading supply chain-based technology and service provider, is utilizing NVIDIA DGX SuperPOD to develop NLP for the application of smart customer service, smart retail, smart logistics, IoT, healthcare, and more.
VinBrain, a Vietnam-based healthcare AI company, has used a DGX SuperPOD to develop and deploy a clinical language model for radiologists and telehealth in 100 hospitals, where it is used by over 600 healthcare practitioners.
Enterprises can experience developing and deploying large language models at no charge in curated labs with NVIDIA LaunchPad.




Leave a Reply