
Xilinx, Inc. introduced Vivado ML Editions, the industry’s first FPGA EDA tool suite based on machine-learning (ML) optimization algorithms, as well as advanced team-based design flows, for significant design time and cost savings. Vivado ML Editions delivers 5x faster compile-time and breakthrough quality of results (QoR) improvements on average 10% on complex designs, compared to […]
xilinxinc
Production-ready, adaptive SOMs aimed at rapid deployment in edge-based applications

Xilinx, Inc. introduced the Kria portfolio of adaptive system-on-modules (SOMs), production-ready small form factor embedded boards that enable rapid deployment in edge-based applications. Coupled with a complete software stack and pre-built, production-grade accelerated applications, Kria adaptive SOMs are a new method of bringing adaptive computing to AI and software developers. The first product available in […]
Adaptive radio platforms designed to meet evolving 5G NR wireless standards

Xilinx, Inc. introduced ZynqRFSoC DFE, a breakthrough class of adaptive radio platforms designed to meet the evolving standards of 5G NR wireless applications. Zynq RFSoC DFE combines hardened digital front-end (DFE) blocks and adaptable logic to build high performance, low power, and cost-effective 5G NR radio solutions for a broad array of use cases ranging […]
Xilinx snags LEAP Gold in Embedded Computing category

The winners of the 2020 LEAP Awards (Leadership in Engineering Achievement Program) were announced last week in a digital ceremony, with products across 12 categories, including embedded computing, power electronics, and test and measurement. Critical to LEAP’s success is the involvement of the engineering community. No one at WTWH Media selected the winners. Instead, our […]
Compute platform targets high-bandwidth cloud apps
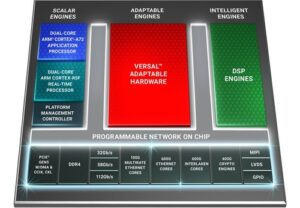
Xilinx, Inc. announced Versal Premium, the third series in the Versal ACAP portfolio. The Versal Premium series features highly integrated, networked and power-optimized cores and the industry’s highest bandwidth and compute density on an adaptable platform. Versal Premium is designed for the highest bandwidth networks operating in thermally and spatially constrained environments, as well as for cloud providers […]
Automotive-qualified 16-nm FPGAs target ADAS, AD applications

Xilinx, Inc. announced the expansion of its automotive-qualified 16 nanometer (nm) family with two new devices – the Xilinx Automotive (XA) Zynq UltraScale+ MPSoC 7EV and 11EG. These two new parts deliver the highest programmable capacity, performance and I/O capabilities enabling high-speed, data aggregation, pre-processing, and distribution (DAPD), as well as compute acceleration for L2+ […]
Community program provides FGPA-design education
element14, an Avnet community, continues to make developing with programmable logic devices easier, quicker and more advantageous for its community of engineers with the launch of its Path II Programmable series, sponsored by Xilinx. Building on the success of last year’s successful training series, Path II Programmable, the only program of its type in the […]
Low-profile PCIe Gen 4 card boosts throughput and power efficiency for data center apps

Xilinx, Inc. expanded its Alveo data center accelerator card portfolio with the launch of the Alveo U50. The U50 card is the industry’s first low profile adaptable accelerator with PCIe Gen 4 support, uniquely designed to supercharge a broad range of critical compute, network and storage workloads, all on one reconfigurable platform. The Alveo U50 […]
IP core enables high-speed communications between FPGAs and MCUs for safety-critical apps

In order to provide more flexibility in how to use safety microcontrollers in automotive and industrial applications, Infineon Technologies AG cooperates with Xilinx Inc. and Xylon, d.o.o.. At the Embedded World trade fair 2019, they present a new Xylon IP core called logiHSSL. It enables high-speed communication between Infineon’s AURIX TC2xx and TC3xx microcontrollers and Xilinx’ SoC, MPSoC and FPGA devices via the […]
RF SoCs cover sub-6-GHz spectrum, direct RF sampling

Xilinx, Inc. today announced it has extended its Zynq UltraScale+ Radio Frequency (RF) System-on-Chip (SoC) portfolio with greater RF performance and scalability. Building on the multi-market success of the Zynq UltraScale+ RFSoC base portfolio, next-generation devices can cover the entire sub-6 gigahertz (GHz) spectrum, which is a critical need for next-generation 5G deployment. They support […]