
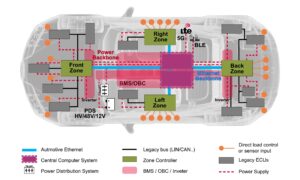
The transition from numerous ECUs to zones will occur over several years from roughly 2025 to 2030. Each OEM will use its own architecture. Long before the smartphone, the number of interconnected electronics and electrical equipment on automobiles, especially high-end vehicles, led pundits to describe a car as a computer on wheels or a digital […]
Featured
What is TinyML?
Data science has not just remained a field of scientific computing and research. In the internet-connected world, data science, machine learning, and artificial intelligence are far more applicable than ever imagined. No doubt, the very first leap in the practical applications of machine learning and artificial intelligence happened when enterprise websites, including social media platforms, e-commerce […]
What are top applications of CAN protocol?
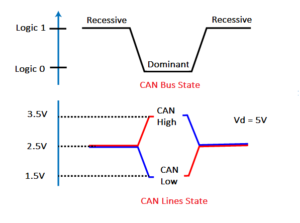
The CAN (controller area network) protocol was developed by the European automotive electronics company Robert Bosch GmbH in 1983 for in-vehicle networks. The intention behind the development of the CAN protocol was to enable robust data communication between different electronic control units (ECU) and microcontroller control units (MCU) of a vehicle on a single wire […]
What are the top tools for developing embedded software?

The embedded software or firmware is the brain of an embedded device. This type of software, however, works differently than conventional forms found on PCs or mobile devices — these are generic and work identically on such operating systems. PC software runs without directly accessing the underlying hardware. The purpose of embedded software works alternatively […]
What is MicroPython?

MicroPython implements the Python 3 programming language for microcontrollers and microcomputers. It is a firmware solution designed to implement the high-level language features of Python into low-level hardware platforms. The firmware is optimized to run in constrained environments while allowing a small subset of Python 3 standard libraries into embedded programming. MicroPython firmware can run […]
The top computer vision tools for embedded systems

Computer vision is reaching new levels, far beyond basic image processing. This is thanks to the integration of artificial intelligence. AI now enables computers and systems to derive meaningful information from digital images that can be used in advanced industries. Currently, one of the most common applications is in security and surveillance. A computer vision […]
5G mmWave test builds on RF best practices
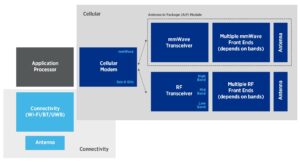
The high level of integration in today’s mmWave phone means traditional test methods no longer apply.
What embedded protocols can you use for optical connectivity?

Communication protocols and protocol stacks like peripheral component interconnect express (PCIe), compute express link (CXL), Aeronautical Radio, Inc. 818 (ARINC 818), Joint Electron Device Engineering Council (JEDEC) standard 204/B/C/D (JESD204B/C/D), Fibre Channel and so on, are formal descriptions of digital message formats and rules. They are separate from the physical transport layer, although some protocols […]
How can you minimize BERs?
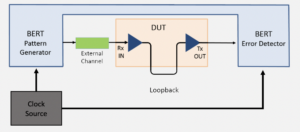
Bit error ratios (BERs, sometimes called bit error rates) measure the ratio of incorrectly received bits in a data stream to the total number of bits in the stream. BERs are an unfortunate fact of life for digital and communication system designers and can be minimized and controlled, but not eliminated. BERs are related to […]
How can TinyML support sustainability on the edge?

Sustainability can be in the eye of the beholder. That’s certainly true for the question of how can TinyML (tiny machine learning) support sustainability on the edge? From a societal perspective, The United Nations Educational, Scientific and Cultural Organization (UNESCO) believes that TinyML can help to achieve its Sustainable Development Goals (SDGs). From an engineering […]